FMD Release Highlights – February 2026
Fabric Metadata‑Driven Framework (FMD) — February 2026 Release Notes
Accelerating Performance, Flexibility, and Data Quality in the Fabric Metadata‑Driven Framework
February brings another round of enhancements to the Fabric Metadata‑Driven Framework (FMD), focusing on deeper automation, better governance, expanded cleansing capabilities, and improved developer experience. While January’s release laid the foundation for performance and configuration flexibility, this month builds on those improvements with more intelligent behaviors, stronger defaults, and cleaner operational workflows.
Faster Notebook Startup Through Library Optimization
One of the most noticeable upgrades is the removal of unnecessary or duplicated libraries, drastically reducing the overhead when loading notebooks.
This is especially beneficial in environments where multiple engineers iterate frequently on pipelines and notebooks. You will immediately observe quicker initialization, smoother interactions, and fewer dependency‑related warnings or conflicts.
Variable Libraries for Configuration – More Flexibility, Less Configuration Drift
A major architectural improvement in this release is the introduction of Variable Libraries for managing configuration settings across notebooks and pipelines.
Why This Matters
Previously, configuration values, especially environment‑specific settings, were scattered across pipelines or injected manually. The new Variable Libraries consolidate these settings into structured, reusable components that:
- Provide clean separation of configuration from code
- Reduce duplication across Development, Test, Acceptance, and Production
- Enable dynamic configuration management during deployments
- Lower the risk of misconfiguration, especially in multi‑workspace environments
The entire framework has been updated to use these new libraries, creating consistency across all notebooks and pipelines.
Default Value Sets Per Environment
The following predefined configuration sets are now included out of the box:
- Development
- Test
- Acceptance
- Production
These defaults accelerate environment setup and make configuration deployment predictable and repeatable.
Setup Notebook Streamlined and Refactored
As part of an ongoing effort to simplify the development experience, the Setup Notebook has been trimmed down, with certain functionalities moved into a dedicated Utilities Notebook.
Benefits
- A more focused Setup Notebook optimized for installation and onboarding
- A Utilities Notebook containing reusable helper functions and maintenance routines
- Clearer separation of concerns
- More intuitive navigation for new users and contributors
This aligns with the broader notebook refactoring seen in the January 2026 update, where improved notebook structure and navigation were also emphasized. Make sure you download the new Setup Notebook.
Data Cleansing Capabilities for Bronze & Silver Layers
A highly requested feature Data Cleansing Rules has now been implemented for both Bronze and Silver layers.
What’s Included
- Built‑in cleansing functions for structural and quality‑related validation
- Automated application of cleansing rules during ingestion and transformation
- Support for:
- Removing invalid rows
- Column-level normalization
- Enforcement of schema and datatype rules
This enhancement significantly boosts the ability to enforce quality at scale and is fully aligned with the framework’s Medallion architecture focus.
As documented in the FMD framework Wiki, cleansing rules can be configured per entity, making them both powerful and flexible for enterprise‑grade data quality requirements.
Updated Pipelines and Notebooks Using the New Variable Libraries
All pipelines and notebooks have been updated to fully adopt the new Variable Library structure.
This provides:
- Reduced maintenance overhead
- Consistent parameterization
- Easier debugging
- Cleaner deployments across environments
This also future‑proofs the framework for upcoming enhancements to the metadata model and environment automation.
Centralized Spark Environment for Better Governance & Control
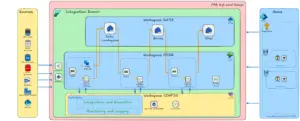
A major architectural improvement this month is the relocation of the Spark Environment to the configuration workspace.
This means:
- One unified Spark Environment shared across all workspaces
- Consistent cluster behavior and performance settings
- Simplified governance, with all Spark policies managed in a single, controlled location
- Easier auditing and change management
- Reduced configuration drift across environments
By centralizing Spark, teams gain better operational consistency while minimizing maintenance overhead. This change also prepares the framework for upcoming governance automation features planned for later releases.
Setup Requirement
Please make sure to use the new Setup Notebook to enable the above functionalities.
Quick Upgrade Checklist
- Download the latest NB_SETUP_FMD notebook. Make you sure you update your configuration settings
- Check the FMD_FRAMEWORK_DEPLOYMENT documentation for more detailed information which settings in the Fabric Admin Portal need to be applied
Bug Fixes & Community Contributions
A huge thank‑you to the community for reporting issues and submitting pull requests! This release includes:
- Minor bug fixes.
- Quality‑of‑life improvements based on your feedback.
Looking Ahead
The February 2026 release is another major step toward making FMD a robust, enterprise‑ready accelerator for Microsoft Fabric. With improved performance, governance, configuration management, and data quality features, the framework continues to mature rapidly—supported by community contributions and real‑world implementation feedback.
If you haven’t yet explored the latest enhancements, now is the perfect time to update your notebooks, pipelines, and environment configurations.
Stay Connected
- https://github.com/edkreuk/FMD_FRAMEWORK
- Hit the subscribe button to get the latest release notes as of the one first in your mailbox


Feel free to leave a comment
Discover more from Erwin | Data & Intelligence
Subscribe to get the latest posts sent to your email.
0 Comments