Speaking at SQL BITS 2022
SQL BITS 2022
Not 1 but 2 sessions
This year I will not present 1 session but 2 sessions.
Data Governance with Azure Purview - Ask the Experts
In this session you have to chance to ask any question on data governance for your business using Azure Purview.
We have a panel of 3 MVPs, Victoria, Wolfgang and myself. Richard we help us out with moderating the session.
If you have an urgent question, feel free to ask it via this form https://forms.office.com/r/dTP38LnmsJ
Of course you can also ask your question live during our session on Friday 11 March from 14:10-15:00. You will find us in room 04.
Looking forward to you all
Lake Database with Database Template and Mapping Data with Azure Synapse Analytics
Microsoft asked me to present a session during SQL Bits in the Cloud Scale Analytics solution area.
Of course I wanted to do that, it is an honor to be asked to do so. Once again thank you Tony and Wee Hyong for inviting me.
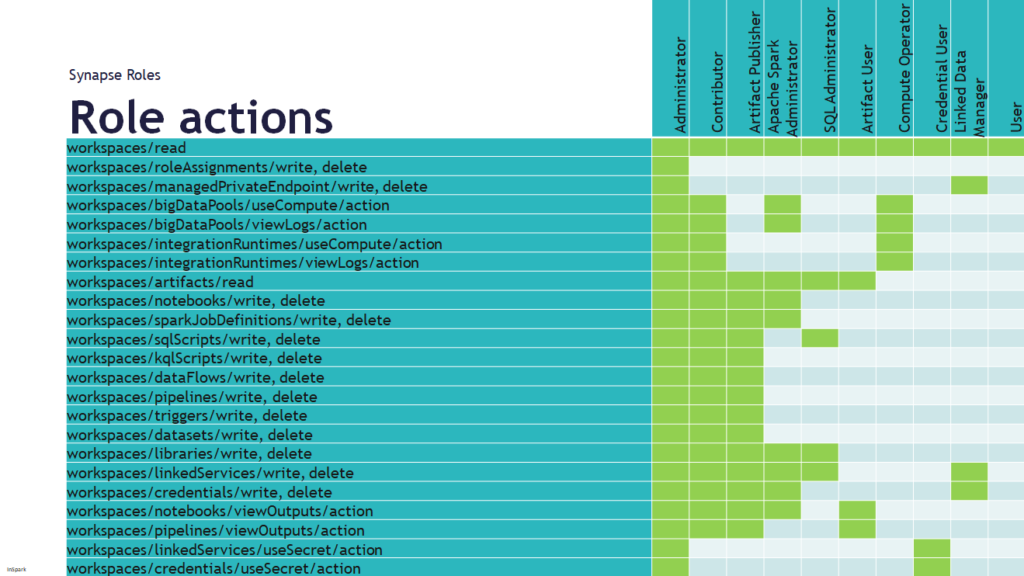
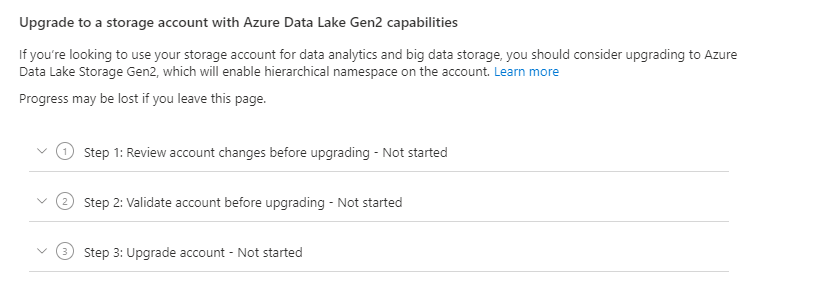
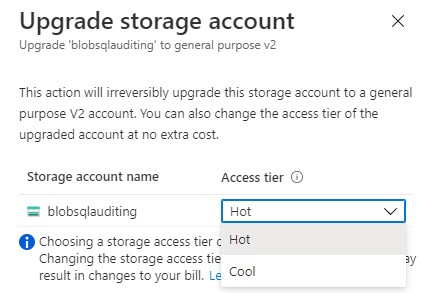
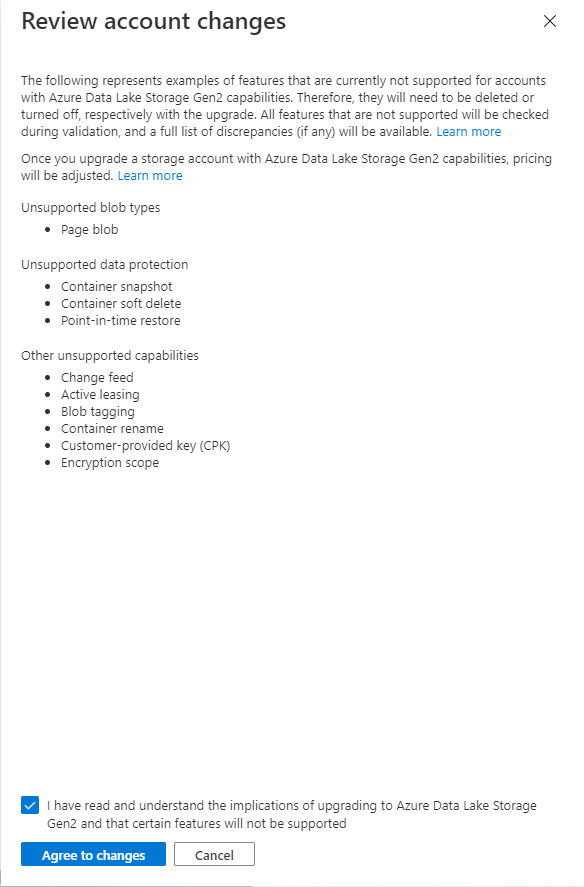
In this session I will take a closer look at Database Template in Azure Synapse Analytics
Database templates in Azure Synapse Analytics are blueprints which can be used by organizations to plan, architect and design solutions.
How can we use these Database Templates in a day-to-day business, in order to speed up to automate this process? Map data tool can help us with that. The map data tool can generate a mapping data flow without having to start from a blank canvas. In this presentation, you will see how this all works in a step-by-step demo-based session.
The session is on Friday 11 March from 12:00-12:50 and will be like the above session in Room 04
Do you want to know more which sessions Microsoft is delivering: Ready for SQLBits 2022? - Microsoft Tech Community
Oh yeah, Thursday 10 March, 9:00 am, the keynote will start, which is being led by Bob Ward, along with Buck Woody, Anna Hoffman, Patrick LeBlanc, Evangeline White, and Pedro Lopes, to show you, from SQL Server on-prem to Azure Data in the cloud, the latest and greatest data platform on earth! You better not miss this one, promises to be a nice keynote.