
Azure Synapse Analytics overwrite live mode
Stale publish branch
In Azure Synapse Analytics and Azure Data Factory is an new option available "Overwrite Live Mode", which can be found in the Management Hub-Git Configuration.
With this new option your can directly overwrite your Azure Synapse Analytics or Azure Data Factory Live mode code with the current Branch from your Azure Dev Ops.
It will use the Publish option to overwrite everything into your Azure Synapse Analytics or Azure Data Factory, so be careful with doing this. If you have a lot of code, the deployment time can take a while based on the size of the branch and the number of resources.
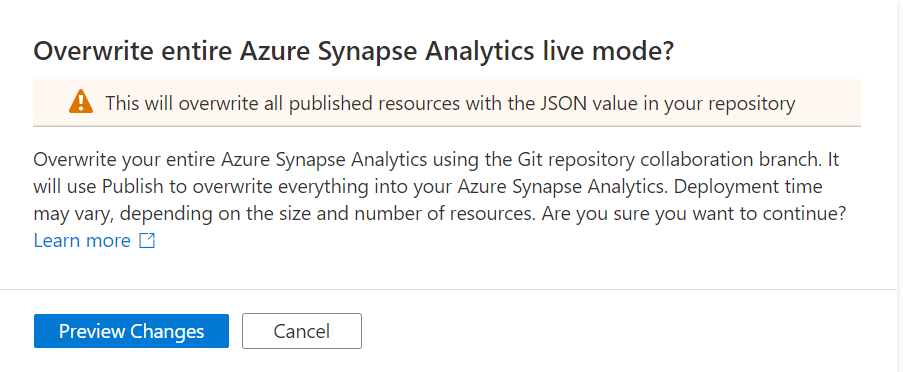
Once you click on Preview Changes you will see that all your code will be published. You need to confirm by clicking the Overwrite button.
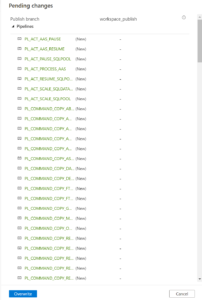
After you clicked on overwrite, it will start publishing.
Why?
Sometimes your Live Mode has a different code than your current Git Branch, especially when it comes to Linked Services, Managed Vnets and when using multiple Feature Branches. Incidentally, this is also the case if you link your code (Solution Templates) to your Azure Synapse Workspace from Dev Ops for the first time. Then it is possible that you will not get this code published because there are still dependencies, what I've seen mostly because the use of Azure Key Vault or different Integration Runtime setup. According to the documentation from Microsoft which you can find here they add the following examples:
- A user has multiple branches. In one feature branch, they deleted a linked service that isn't AKV associated (non-AKV linked services are published immediately regardless if they are in Git or not) and never merged the feature branch into the collaboration branch.
- A user modified the Synapse or data factory using the SDK or PowerShell
- A user moved all resources to a new branch and tried to publish for the first time. Linked services should be created manually when importing resources.
- A user uploads a non-AKV linked service or an Integration Runtime JSON file manually. They reference that resource from another resource such as a dataset, linked service, or pipeline. A non-AKV linked service created through the UX is published immediately because the credentials need to be encrypted. If you upload a dataset referencing that linked service and try to publish, the UX will allow it because it exists in the git environment. It will be rejected at publish time since it does not exist in the Synapse or data factory service.
If the publish branch is out of sync with your collaboration branch and contains out-of-date resources despite a recent publish, you can use the solution above.
Conclusion
I used to disconnect my Git configuration, make the changes in Live Mode, and reconnect Azure Dev Ops again and imported the resource to my current Branch. This solution makes it much easier and will safe you definitely a lot of time.
If you haven't yet linked your Azure Synapse Workspace to Azure Dev Ops, read how to do this in a previous Blog.
Hopefully this article has helped you a step further. As always, if you have any questions, leave them in the comments.
- Fabric Metadata Driven Framework July 2026 Release Notes

- Reassigning Microsoft Fabric Capacities in Bulk: Don’t Let an Expiring Trial Catch You by Surprise
- Bringing Column-Level Lineage from Microsoft Fabric to Microsoft Purview with FMD
- My first experience: Building a Fabric App

- Fabric Metadata Driven Framework update May 2026

Feel free to leave a comment
15 Comments
Leave a Reply
Discover more from Erwin | Data & Intelligence
Subscribe to get the latest posts sent to your email.
Hi Erwin,
Can you confirm what permission is required to “Overwrite Live Mode”, cannot find any docs on this and we have synapse admin RBAC but the button is greyed out
Hi Corbin,
Great question, you need to have the contributor or owner role on the Synapse workspace.
Thanks for the quick reply erwin,
Im attempting to change the publish branch from workspace_publish to master using the publish_config.json file as instructed by MSFT, surprise… it doesnt work 🙁
Do you have any experience changing the publish branch
Corbin,
My advice is not change the workspace_publish branch to main or master . Leave as is or change it to xxxxx_publish. To do that add a file name publish_config.json in your collaboration branch(develop) with the desired name.
Update your collaboration branch and click on publish. Your new publish branch will automatically be created. Or create in DevOps a new publish branch and assign this branch in your Synapse workspace through the git configuration-settings. Let me know if this worked well for you.
Erwin,
What is the reasoning behind this please?
I followed bradley balls guide here
https://techcommunity.microsoft.com/t5/data-architecture-blog/ci-cd-in-azure-synapse-analytics-part-3/ba-p/1993201
More specifically this comment:
”
Hi Chris, You are spot on. I meant to change workspace_publish to main and should have done so on the blog. I need to check with Buck, I do not have the ability to edit the post. My preference is for the JSON generated with the workspace to go straight to main. This can trigger a new build process in a more automated fashion consistent with CICD principals.
”
I have managed to change the branch now, it appears the publish_config needs to be in the synapse workspace root folder as defined in git config and not in the repository root as i originally thought
I am finding issues probably like yourself where the dev/deploy process for synapse is still very much in its infancy and documentation is poor or non-existent
Corbin,
There are more ways to follow, as long there’s no automated publish functionality for Azure Synapse we use this approach. We publish Synapse to the workspace_publisg branch and create the release pipeline on that branch with approval gates to test/acceptance and production. This is different approach for other Azure Data Services we follow within our develop or main branch, we’re we use PR’s.
It al depends on what you’re used to. Bradley’s way is a way to go, but they’re any many others. I do like the way Bradley is doing it and definitely going to have a look into it.
Erwin,
Thanks for taking the time to reply, its really helping me and i hope our conversation may help others too..
I ended up switching the publish branch back to `workspace_publish` due to hitting a permissions error when setting the branch to master, basically it was requiring us to allow push master perms for the user, this would pretty much void all PR policies so we reverted back to the default workspace_publish, i have posted a comment on bradleys blog asking how he handled this.
I now have the templates successfully deploying to the Dev environment “WINNER!”, i am now getting ready to deploy to the release environment but i have a concern/query.
I have overridden the ARM template parameters in TemplateParametersForWorkspace.json as required so this all seems fine, however i have noticed in the TemplateForWorkspace.json file we have 346 references to our dev environment, these look to be sqlPool references and the like e.g.
within the pipelines section under ifTrueActivities there is a reference to the sqlPool for our dev environment see pastebin https://pastebin.com/0QQLbJr2
question is, does the extension “magically” sort this out or do i need to override each of these params using https://docs.microsoft.com/en-us/azure/synapse-analytics/cicd/continuous-integration-delivery#custom-parameter-syntax
Do you have any experience with this?
Erwin,
Thank you again for taking the time to discuss this with me, its really appreciated
I have resolved this by naming the sparkPool and sqlPools the same across all environments, it seems this is the recommended approach,
https://craigporteous.com/adventures-in-ci-cd-with-azure-synapse-data-toboggan-session/
The above article/video really helped me with this..
It seems if you do not have these pools named the same you need to use a custom template file which is very code heavy and not exactly simple..
I am going to create a blog post documenting my journey and the challenges faced in the hope it will help others, i will reference yours and craigs article as they have really helped me and MSFT documentation misses key points
Thank you again for you help
Great to hear Corbin,
Yes you need to have the same names for spark and sql pools. If you use custom Azure IR of Self Hosted IR, you must have also the same name across all your environments. If you going start using the Data Explorer pool, same situation
Looking forward to your blogpost
Hi Erwin,
Me again
I am still running into concerns, (though ive not actually tried a release deployment yet)
In the generated ARM templates there are still references to the dev environment, these are things like notebooks etc..
The spark pool name is the same across all environments but the resource group and subsequent workspace are still pointed to dev
example
“a365ComputeOptions”: {
“id”: “/subscriptions/subId/resourceGroups/devcoresynapseuksrg/providers/Microsoft.Synapse/workspaces/devsynws01uks/bigDataPools/zpspk01”,
“name”: “zpspk01”,
“type”: “Spark”,
“endpoint”: “https://devsynws01uks.dev.azuresynapse.net/livyApi/versions/2019-11-01-preview/sparkPools/zpspk01”,
Also keyvault references are dev related also..
I cant see how it just works this out, but it must do? coz you cant use the same resource group and workspace name across environments
Am i missing something?
Corbin,
Workspace names are automatically overruled when deploying your workspace when you use the Extension from the marketplace https://marketplace.visualstudio.com/items?itemName=AzureSynapseWorkspace.synapsecicd-deploy
Keyvault or other Linked Services needs to be Override, this can also be done in the template
-LS_KEYVAULTNAME_properties_typeProperties_baseUrl https://xxxxxxxxxx.vault.azure.net/ -LS_ADLS_DLS2_properties_typeProperties_url https://xxxxxxxxxx.dfs.core.windows.net
For a sql connection use a KeyVault secret and create a secret with the same name in every KeyVault in every environment.
Hopefully this will help you with the next steps. If not let me know.
Hi Erwin –
Have you experienced times where “Overwrite live mode” doesn’t work and you must resort to the sequence of operations you describe in your Conclusion? I’m referring to this part:
“disconnect my Git configuration, make the changes in Live Mode, and reconnect Azure Dev Ops again and imported the resource to my current Branch”
Thank you!
Christina,
I sure have. Especially if a lot of changes have taken place in the Pipelines. Renaming Pipelines as an example. The solution that often works is to simply delete the code in Live Mode and overwrite it again with that from the Branch, using the overwrite option. Have you ever tried that?
Thank you for your quick response, Erwin! This confirms something we have been seeing when making updates to non-AKV linked services. Sometimes overwrite live mode works, but sometimes we have to manually update the linked service connection fields to match what they are in our collaboration branch.
We have what may be a funny follow-up question: when you say “delete the code in Live Mode”, do you mean clicking the object’s trashcan icon while in Live Mode or actually deleting code? It seems like the former would work well, but wondering if you use Powershell or similar to do it quicker?
Yes I mean in live mode so first you need to disconnect your repo. Removed the pipelines causing problems. Reconnect the repository.
Or disconnect, change your pipeline, reconnect the repo, but make sure to check the “Import existing resources to repository” box. The code in your live mode will now be imported into your branch. You can do it with Powershell, but make sure you have removed all related objects as well. If you do this in Live mode, you will immediately see the related objects. Hopefully this answers your question.