
How to use notebookutils.notebook.runMultiple in Notebooks in Microsoft Fabric?
In the previous blog post we explored how to use the PySpark Executor. However, sometimes you may need to run multiple notebooks in a specific order or in parallel, depending on the dependencies and logic of your data pipeline. For example, you may have a notebook that preprocesses the data, another notebook that trains a machine learning model, and another notebook that evaluates the model and generates a report. How can you orchestrate these notebooks in Microsoft Fabric?
The answer is notebookutils.notebook.runMultiple, a built-in function that allows you to run multiple notebooks in parallel or with a predefined topological structure. With notebookutils.notebook.runMultiple, you can:
- Execute multiple notebooks simultaneously, without waiting for each one to finish.
- Specify the dependencies and order of execution for your notebooks, using a simple JSON format.
- Optimize the use of Spark compute resources and reduce the cost of your Fabric projects.
In this blog post, I will show you how to use notebookutils.notebook.runMultiple with DAG (Directed Acyclic Graph) in Notebooks in Microsoft Fabric to achieve high concurrency, flexibility, and scalability.
What is notebookutils.notebook.runMultiple()?
The method notebookutils.notebook.runMultiple() allows you to run multiple notebooks in parallel or with a predefined topological structure. The API is using a multi-thread implementation mechanism within a spark session, which means the compute resources are shared by the reference notebook runs. With notebookutils.notebook.runMultiple() , you can:
- Run multiple notebooks in parallel, without any dependency or order among them.
- Run multiple notebooks in a DAG, where each notebook can depend on the output of one or more previous notebooks.
- Pass parameters to the notebooks, such as input data, configuration, or variables.
- Get the output of the notebooks, such as return values, metrics, or logs.
How to use notebookutils.notebook.runMultiple()?
To use notebookutils.notebook.runMultiple() , you need to follow these steps:
- Create the notebooks that you want to run. You can use any language that is supported by Fabric, such as Pyspark(Python), Scala, or R. Make sure to save your notebooks in the same workspace or folder, and give them meaningful names. For example, you can create three notebooks: NB_LOAD_1, NB_LOAD_2 and NB_LOAD_3. Or you can just use 1 Notebook and execute the Notebook with different parameters.
- Define the DAG of your notebooks. You can use a Python dictionary to specify the dependency and order of your notebooks. The keys of the dictionary are the names of the notebooks, and the values are lists of the names of the notebooks that they depend on. For example, you can define a DAG like this:
Run multiple notebooks in parallel
Simple example of using notebookutils.notebook.runMultiple to run multiple notebooks in parallel, you can pass a list of notebook as input.
notebookutils.notebook.runMultiple(["NotebookSample1", "NotebookSample2"]) Run multiple notebooks with parameters sequential/in parallel
Run multiple notebooks with parameters sequential/in parallel
from notebookutils import notebookutils
DAG = {
"activities": [
{ "name": "NB_Bronze_Silver_Logging", # activity name, must be unique
"path": "NB_Bronze_Silver_Logging", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"source_schema": "Application","source_name": "People","sourceLakehouse": "xxxxxxxxx",
"target_schema": "Application","target_name": "People","targetLakehouse": "xxxxxxxxxx",
"NotebookExecutionId": NotebookExecutionId,
'useRootDefaultLakehouse': True}, # notebook parameters
#"workspace": "workspace1", # workspace name, default to current workspace
"retry": 1, # max retry times, default to 0
"retryIntervalInSeconds": 30, # retry interval, default to 0 seconds
#"dependencies": [] # list of activity names that this activity depends on
},
{ "name": "NB_Bronze_Silver_Logging_1", # activity name, must be unique
"path": "NB_Bronze_Silver_Logging", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"source_schema": "Application","source_name": "PaymentMethods","sourceLakehouse": "xxxxxxxxx",
"target_schema": "Application","target_name": "PaymentMethods","targetLakehouse": "xxxxxxxxxx",
"NotebookExecutionId": NotebookExecutionId,
'useRootDefaultLakehouse': True}, # notebook parameters
#"workspace": "workspace1", # workspace name, default to current workspace
"retry": 1, # max retry times, default to 0
"retryIntervalInSeconds": 0, # retry interval, default to 0 seconds
#"dependencies": [] # list of activity names that this activity depends on
},
{ "name": "NB_Bronze_Silver_Logging_2", # activity name, must be unique
"path": "NB_Bronze_Silver_Logging", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"source_schema": "Application","source_name": "DeliveryMethods","sourceLakehouse": "xxxxxxxxx",
"target_schema": "Application","target_name": "DeliveryMethods","targetLakehouse": "xxxxxxxxxx",
"NotebookExecutionId": NotebookExecutionId,
'useRootDefaultLakehouse': True}, # notebook parameters
#"workspace": "workspace1", # workspace name, default to current workspace
"retry": 1, # max retry times, default to 0
"retryIntervalInSeconds": 0, # retry interval, default to 0 seconds
#"dependencies": [] # list of activity names that this activity depends on
}
],
"timeoutInSeconds": 43200, # max timeout for the entire pipeline, default to 12 hours
"concurrency": 0 # max number of notebooks to run concurrently, default to unlimited
}
notebookutils.notebook.runMultiple(DAG)
Name: Name of the NotebookActivity, must be unique
Path: Name of the Notebook
Args: Notebook Parameters
Retry: Number of Retries when Notebook fails
Dependencies: List of NotebookActivity names that this activity depends on
The great functionality of using the RunMultiple is that you have a progress bar and a direct overview which Notebook has run successfully and which one has failed. When using the exitvalue
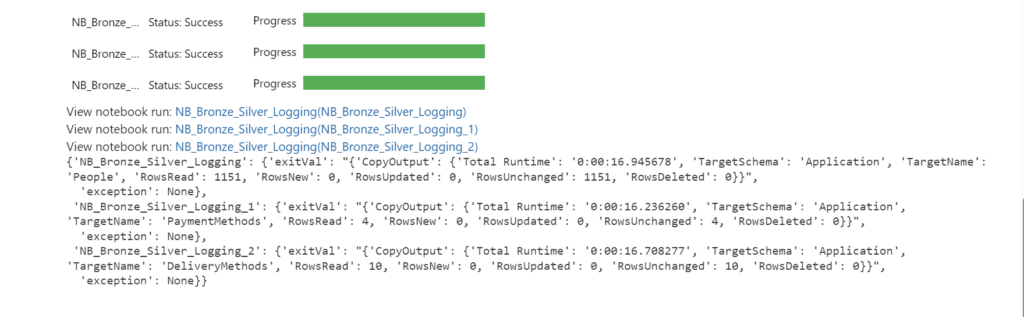
Conclusion
In this blogpost, I showed you how to use notebookutils.notebook.runMultiple() to run multiple notebooks in parallel or with a DAG in Fabric. This method can help you achieve high concurrency, flexibility, and scalability for your data processing workflows. I hope you found this blogpost useful and informative. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading!
If you want to learn more from notebookutilscheck the following link NotebookUtils (former MSSparkUtils) for Fabric
NOTE
- MsSparkUtils has been officially renamed to NotebookUtils. The existing code will remain backward compatible and won't cause any breaking changes. It is strongly recommend upgrading to notebookutils to ensure continued support and access to new features. The mssparkutils namespace will be retired in the future.
- NotebookUtils is designed to work with Spark 3.4(Runtime v1.2) and above. All new features and updates will be exclusively supported with notebookutils namespace going forward.
- Fabric Metadata Driven Framework July 2026 Release Notes

- Reassigning Microsoft Fabric Capacities in Bulk: Don’t Let an Expiring Trial Catch You by Surprise

- Bringing Column-Level Lineage from Microsoft Fabric to Microsoft Purview with FMD
- My first experience: Building a Fabric App
- Fabric Metadata Driven Framework update May 2026


Feel free to leave a comment
Discover more from Erwin | Data & Intelligence
Subscribe to get the latest posts sent to your email.
0 Comments