Microsoft Fabric SQL Database my first experience
Microsoft
Microsoft Announces Public Preview of SQL Database in Microsoft Fabric
Microsoft has announced the Public Preview of the SQL database in Microsoft Fabric, a significant step towards simplifying and accelerating AI app development. This new service is designed to be simple, autonomous, secure, and optimized for AI, making it easier for developers to build AI applications. Today i had a quick look and was very impressed.
Key Highlights:
- Simplicity: The SQL database in Fabric is designed to be user-friendly, reducing the complexity typically associated with database management.
- Autonomy: It offers autonomous features that handle routine tasks, allowing developers to focus more on innovation.
- Security: Enhanced security measures ensure that data is protected, meeting the highest standards.
- AI Optimization: The service is optimized for AI, providing the necessary tools and infrastructure to support AI-driven applications.
Benefits:
- Faster Development: Developers can build AI apps up to 71% faster and more effectively.
- Unified Platform: Fabric evolves from an analytics platform to a comprehensive data platform, integrating operational databases seamlessly.
Hands-On Experience:
Today, I took the opportunity to get some hands-on experience with this new database in my environment. Setting up the database was incredibly easy and took less than a minute. Here’s a quick guide to get you started:

- Click on "New Item".
- Select "SQL Database" and define a name (I always start with SQL_).
- After 60 seconds, your database is ready to use.
To connect to the database, if you are using tools like SSMS, make sure to add the database name to the connection pane to avoid errors related to the master database.

Once connected, you can perform your day-to-day SQL server tasks with ease. Additionally, you can use the database as a source or sink in Data Flows and Pipelines with copy activity and stored procedures activities in Microsoft Fabric or start building an API on top of your data.
I deployed my database project file from Azure Data Studio to the newly created database and that took only like 5 seconds. Next is to copy the data over. I tried to restore a dacpac or bacpac file, but did not succeed yet so far. After that, I connected my database to Git and you know what, all my objects from the database are in there. Awesome!"
For more details, including demo videos and customer testimonials, check out the full blog post here.
Conclusion:
The Public Preview of the SQL database in Microsoft Fabric is a game-changer for developers looking to build AI applications. Its simplicity, autonomy, security, and AI optimization make it an invaluable tool for accelerating development and enhancing productivity. As Microsoft continues to innovate and expand its offerings, the SQL database in Fabric stands out as a testament to the company's commitment to providing cutting-edge solutions for the modern developer. I'm definitely going to use this new database for my Meta Data driven Framework, no Azure SQL Deployment, network setup, Private endpoint setup anymore, just start and connect.
SQL database in Fabric will be free until January 1, 2025, after which compute and data storage charges will begin, with backup billing starting on February 1, 2025.
Next
Microsoft Learn: Implement operational databases in Microsoft Fabric
Get Started
This is a live learning session where you can ask questions and learn all of the basics of SQL database and Microsoft Fabric in one course, register here.
Learn Together: SQL database in Fabric
- Fabric Metadata Driven Framework July 2026 Release Notes

- Reassigning Microsoft Fabric Capacities in Bulk: Don’t Let an Expiring Trial Catch You by Surprise
- Bringing Column-Level Lineage from Microsoft Fabric to Microsoft Purview with FMD
- My first experience: Building a Fabric App
- Fabric Metadata Driven Framework update May 2026






 Enable High Concurrency in WorkspaceOnce enabled, all notebook sessions triggered by pipelines will be packed into high concurrency sessions automatically.
Enable High Concurrency in WorkspaceOnce enabled, all notebook sessions triggered by pipelines will be packed into high concurrency sessions automatically. Create Pipeline with Notebook Activity
Create Pipeline with Notebook Activity Enable session tag on Notebook
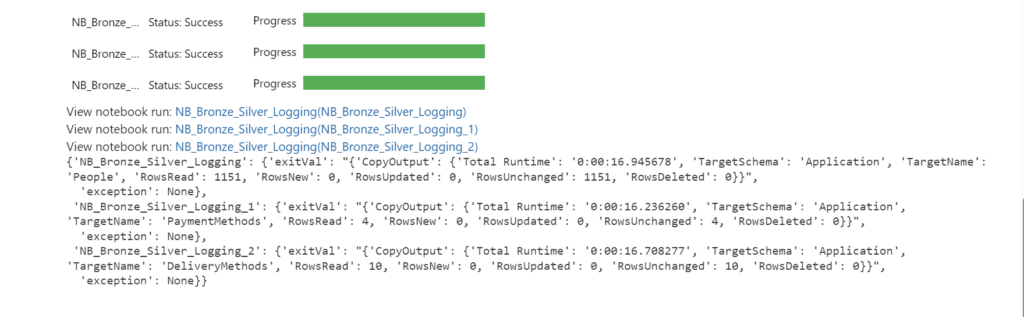
Enable session tag on Notebook Notebook Execution before session startedBelow an overview in the Monitor when the session started
Notebook Execution before session startedBelow an overview in the Monitor when the session started Notebook Execution when session startedOverview of all the executed Notebooks
Notebook Execution when session startedOverview of all the executed Notebooks Notebook Execution when session was finished
Notebook Execution when session was finished


 In the afternoon, I hosted my own session Microsoft Fabric: Building a Data Ingestion and Processing framework to Drive Efficiency in a packed room. Thank you all for attending, engaging, and asking questions. As promised, you can find the session code on my
In the afternoon, I hosted my own session Microsoft Fabric: Building a Data Ingestion and Processing framework to Drive Efficiency in a packed room. Thank you all for attending, engaging, and asking questions. As promised, you can find the session code on my