AutoResolveIntegrationRuntime!
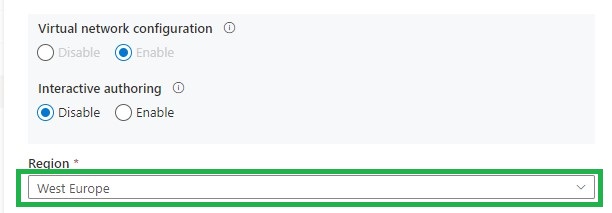
The last few days I’ve been following some discussions on Twitter on using a separate Integration Runtime in Azure Synapse Analytics running in the selected region instead of auto-resolve. The AutoResolveIntegrationRuntime is automatically deployed with Auto Resolve and cannot be changed. If you create a separate Integration Runtime you can set the Region.
The blog from Asanka Padmakumara has a good explanation why should you choose for a new Integration Runtime with a dedicated Region so I’m not going in detail of that.
I was more interested what this will do with the costs when Managed Virtual Network is enabled and run a certain Pipeline with AutoResolveIntegrationRuntime enabled or with a manual created Integration Runtime. The final result was quite surprising for me.
Case:
Azure Synapse Analytics deployed with Managed Virtual Network and Private Links in West-Europe region.
Copy data from a Azure SQL server to Datalake.
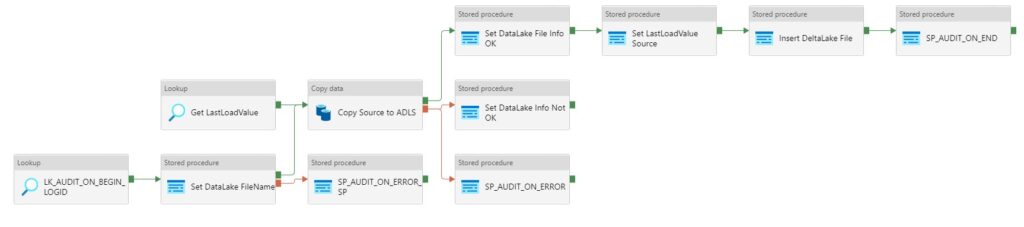
Result:
Pipeline Consumption with AutoResolveIntegrationRuntime

Pipeline Consumption with Integration Runtime created in West-Europe

I didn’t expect the consumption of these 2 Integration Runtimes to be different.
The next step is how does that compare in terms of costs based on the Azure Price Calculator. In the example below, I did the calculation based on above pipelines and that the pipeline has run 1 month every day(30days).
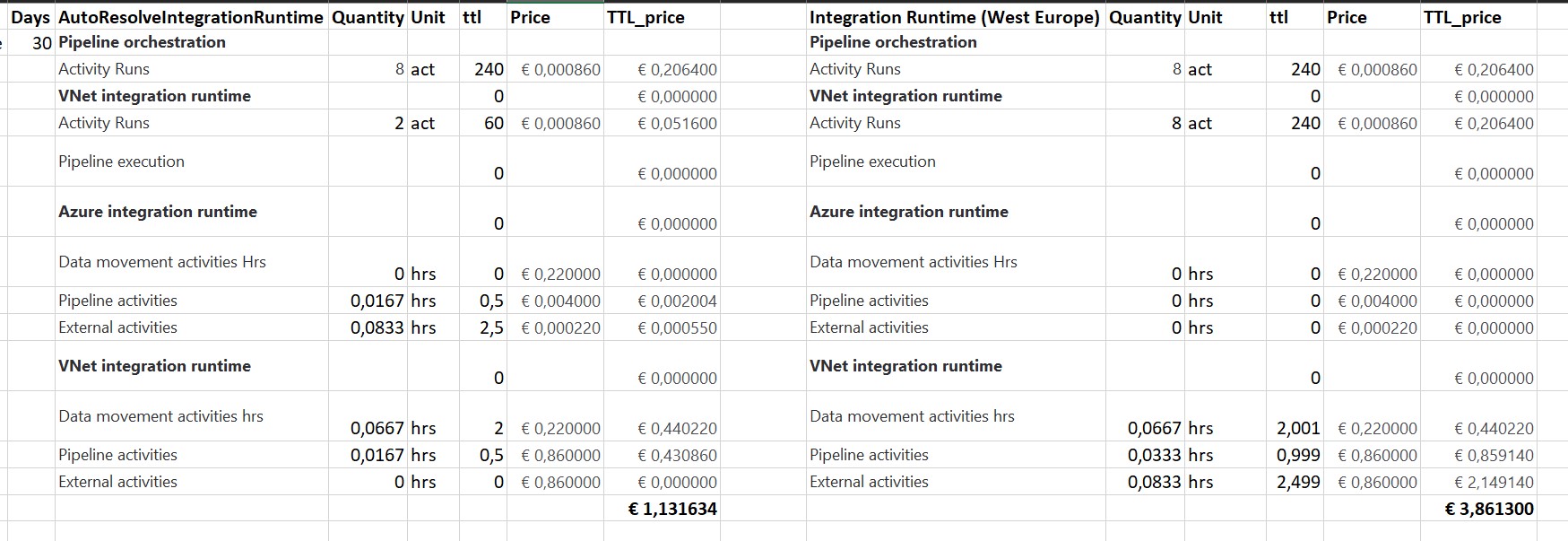
Conclusion:
When running all my Linked Services on the AutoResolveIntegrationRuntime it looks to be a little bit faster compared to an Integration Runtime created in West-Europe. But there was a huge difference in costs, you have to pay 350% more if you run on an Integration Runtime. That is quite a lot, especially if you run 100 of these Pipelines per day, which is almost € 270 on a monthly basis. These differences probably won’t be there if you don’t use the Managed Virtual Network.
Remarks:
During my test of the Integration Runtime I also found out that you cannot change a DataFlow in Azure Synapse Analytics to an Integration Runtime without auto resolve.

If you enable Managed Virtual Network for auto-resolve Azure IR, the IR in the Data Factory or Synapse Workspace region is used.
=> Integration runtime – Azure Data Factory & Azure Synapse | Microsoft Docs
As always, if you have any questions, let me know.
Discover more from Erwin | Data & Intelligence
Subscribe to get the latest posts sent to your email.