Thanks everyone for visiting my session during SQLBits. It's great to see such a full room and that so many people have started using Microsoft Purview.
SLIDES
The slides can be downloaded via the link below, so that you can view them again at home. It could well be that it was a lot of information in 20 minutes. If you have any questions, be sure to let me know.
In my previous blog, I wrote how you can share data within your organization or across organizations. Now it's time to have a look how the lineage will look like.
In this article I will explain the Microsoft Purview Data Sharing Lineage and not the Lineage for Azure Data Share. This can be found here.
Data lineage is the ability to track the flow of data from its source to its destination, including any transformations or processing that occur along the way. Lineage is important for several reasons. First, it can help businesses ensure the accuracy and quality of their data. By tracing the lineage of a particular piece of data, businesses can identify any errors or inconsistencies that may have been introduced during processing.
Lineage is also important for compliance and regulatory purposes. Businesses may be required to track the lineage of certain types of data in order to comply with regulations or to demonstrate the integrity of their data.
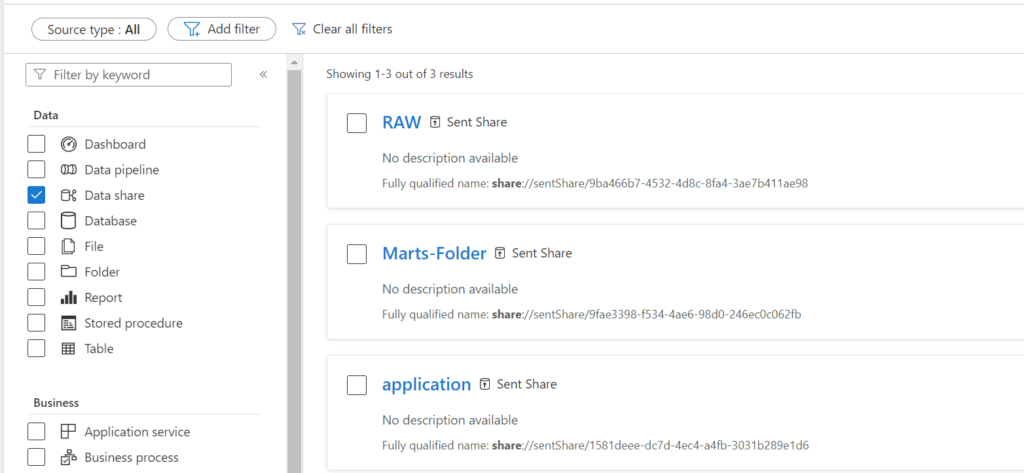
Data share assets discovery
Data share assets can now be discovered in the Microsoft Purview Catalog. The Data share asset label is as of today available as a new filter option.
The Data share assets include sent share and received share assets and users can see the properties such as share metadata, owners, contact information, etc.
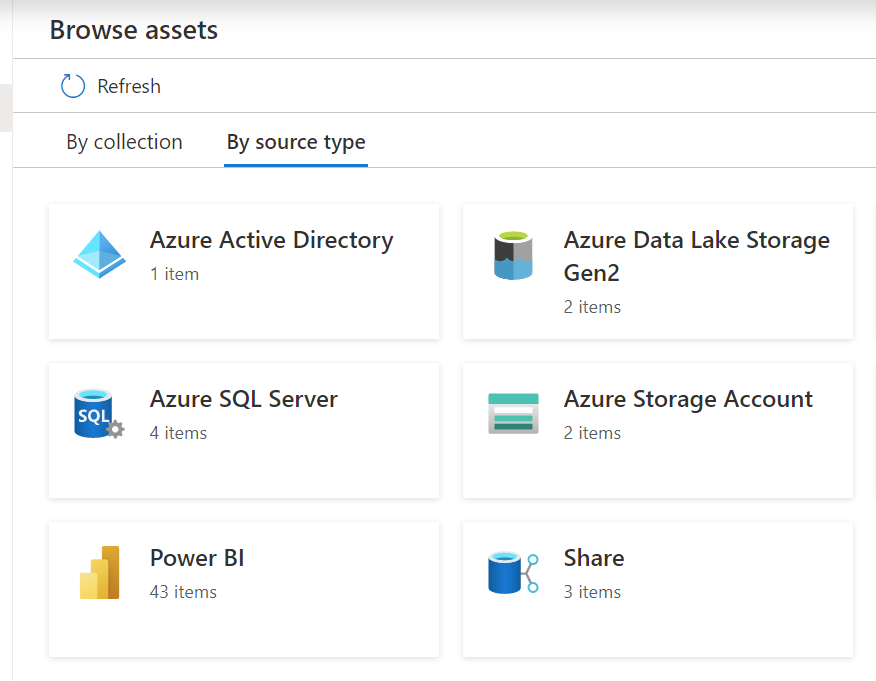
Azure Active Directory (AAD) tenant assets can be discovered in the catalog for all the tenants the current user tenant has sent or received data shares, to see the tenant-level Data Sharing Lineage.
As you can see when browsing all the assets, you will discover 2 new types over here, Azure Active Directory and Share.
Data Share Lineage
Data Sharing lineage aims to provide detailed information for root cause analysis and impact analysis.
Some common scenarios include:
Full view of datasets shared in and out of your organization
Root cause analysis for upstream dataset dependencies
Impact analysis for shared datasets
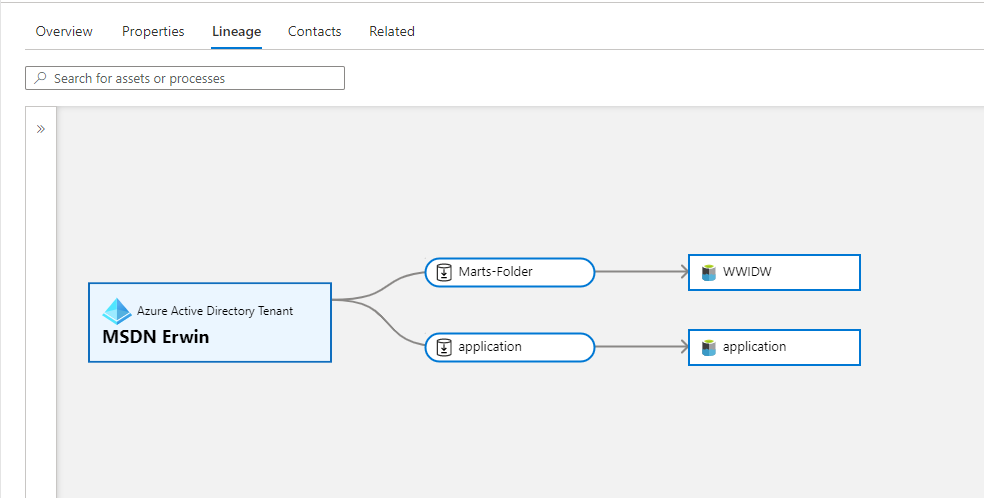
Lineage overview from the Data Receive Share view. As you can see, there is a new asset "Azure Active Directory Tenant", in this case you will see from which tenant the data is coming from.
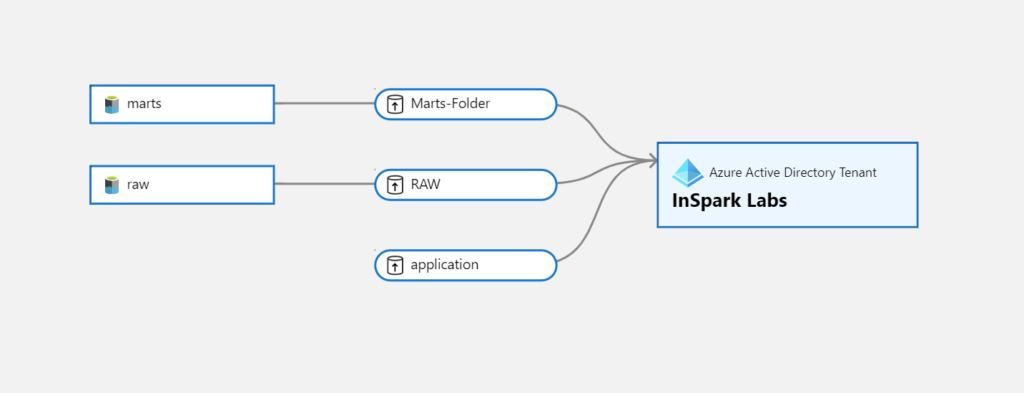
Below you see an overview of the lineage where we created the Share and to which tenant we shared the data to. As you can see, the lines of the AAD tenant are opposite of each other, so you can clearly see what is being shared and what is the receiving location.
Conclusion
Microsoft Purview's lineage capabilities are a powerful tool for businesses that need to track the flow of their data. By providing a complete view of data lineage, Purview can help businesses ensure the accuracy and integrity of their data, comply with regulatory requirements, and improve the efficiency of their data processing workflows.
Thanks for reading and like always, if you have any questions leave them in the comments.
FabCon Atlanta 2026 made one thing unmistakably clear: Microsoft Fabric has crossed the line from promise to production.
This was not a conference full of “what’s coming next.” It was a conference about what is ready.
With roughly 80% of announced capabilities reaching General Availability (GA), Fabric is no longer approaching enterprise readiness. It is an enterprise platform, designed, secured, and governed for the AI era.
What mattered most was not the number of announcements, but which capabilities went GA: centralized security, enterprise networking patterns, OneLake governance, and platform-grade CI/CD. These are not nice-to-haves. These are the foundations enterprises require before scaling analytics and AI responsibly.
Let’s unpack why this matters.
Enterprise AI Starts With Secure, Governed Data
AI amplifies everything, value and risk.
As models become more capable, the importance of controlled data access, policy enforcement, and end-to-end governance becomes non‑negotiable. At FabCon, Microsoft made a clear architectural statement:
OneLake is the enterprise data backbone for AI and security is enforced once and applied everywhere.
This represents a fundamental shift. Not tool-level security. Not fragmented enforcement. But platform-level control.
For enterprises moving beyond experimentation into AI at scale, this distinction is critical.
Network Security: Designed for Enterprise Boundaries
Real enterprises do not operate in open, internet-exposed architectures. They operate in hybrid, regulated, and security-sensitive environments and Fabric is increasingly aligned with that reality.
Fabric’s enterprise networking direction became unmistakable, reinforcing principles such as:
Alignment with Zero Trust networking models
Private endpoints and private links
Outbound access protection for external shortcuts
Workspace IP firewalling
Resource instance rules restricting access to designated Azure resources
Rather than forcing customers into overly permissive designs, Fabric is evolving toward network-aware data platform patterns that fit inside enterprise boundaries.
This matters even more for AI workloads, where sensitive data is accessed by notebooks, agents, pipelines, and downstream applications at scale.
Microsoft is deliberately avoiding security sprawl, but the direction is clear: Fabric is designed to live inside enterprise networks, not around them.
OneLake: One Logical Data Estate, Not Another Copy
OneLake has matured rapidly into the single logical data layer for Microsoft Fabric and by extension, for enterprise AI.
What makes OneLake enterprise-grade is not unification alone, but how that unification is achieved:
Zero-copy shortcuts and mirroring reduce data duplication
Data remains in place while becoming analytics and AI accessible
Enterprises avoid the classic sprawl of unmanaged data copies
Microsoft reinforced that OneLake is not a convenience feature. It is the governed foundation upon which analytics, BI, and AI agents operate.
AI models do not just need data. They need trusted, current, policy-compliant data.
OneLake is how Fabric delivers that trust at scale.
One of the most important GA milestones announced at FabCon was OneLake Security.
For years, enterprises have struggled with an obvious question:
Why does the same dataset require different security definitions for Spark, SQL, and Power BI?
OneLake Security directly addresses this problem.
With OneLake Security:
Access policies are defined once
Enforcement is consistent across Spark, SQL, Power BI, and AI workloads
Governance moves from tool-specific configuration to platform-wide control
This “secure once, enforce everywhere” model is foundational for enterprise AI where the same data is reused across multiple engines, workloads, and autonomous agents.
Additional signals of maturity:
Mirrored databases are already in Preview
Eventhouse integration is coming
OneLake Security APIs are on the roadmap, enabling any engine to integrate with the same security model
This is not incremental improvement. This is platform consolidation.
OneLake Governance: From Discovery to Responsible AI
Enterprise AI rarely fails because the model is weak.
It fails because governance is fragmented or invisible.
Microsoft made it clear that OneLake is not just a storage abstraction, it is a governed data foundation designed for responsible AI adoption at scale.
With key governance capabilities now generally available, governance is no longer an afterthought or an external dependency.
Governance Embedded in the Data Experience
A major step forward is the OneLake Catalog Govern experience, which brings governance signals directly into data discovery and consumption.
Instead of asking users to check governance elsewhere, Fabric surfaces context by default, including:
Clear ownership and accountability
End-to-end lineage across ingestion, transformation, and consumption
Sensitivity labels and policy inheritance across Fabric workloads
This closes a long-standing enterprise gap.
The question is no longer: “Can I find the data?”
It becomes: “Can I safely use this data for this purpose?”
That shift is essential for AI.
Data Sovereignty: Customer Managed Keys at Platform Scale
With Customer Managed Keys (CMK) available across almost every Fabric workload, Microsoft Fabric now meets a core requirement for enterprise data sovereignty. Encryption keys remain fully under customer control, enabling organizations to meet regulatory, contractual, and regional sovereignty requirements without fragmenting the platform.
CMK everywhere removes one of the last structural blockers for adopting Fabric in highly regulated and security‑sensitive environments.
Fabric CI/CD: From Analytics to Platform Engineering
Another strong indicator of Fabric’s enterprise maturity is its evolution toward platform engineering and CI/CD.
At FabCon Atlanta, it became clear that Fabric is no longer optimized solely for interactive development. It now supports:
Source-controlled artifacts
Repeatable, automated deployments
Clear environment separation (dev / test / prod)
Alignment with existing enterprise DevOps practices
The new release of the Fabric CLIv1.5 introduces the deploy command, which wraps the fabric-cicd Python library and exposes it as a single CLI operation. The CLI integrates with fabric-cicd so deploying items from a Git-connected workspace to a target workspace
This is critical for AI scenarios, where experimentation must transition into governed, auditable production pipelines.
With Fabric CI/CD, data and AI assets are treated as first-class software products not ad-hoc analytics outputs.
From Features to Platform: Why GA Changes Everything
Preview features are exciting. GA features are trustworthy.
The fact that the majority of FabCon Atlanta announcements reached GA sends a strong signal to enterprise decision-makers:
Fabric is stable, supported, and ready for mission-critical workloads.
That matters even more in the AI era, where:
Data exposure risks are higher
Regulatory scrutiny is increasing
Operational reliability is non-negotiable
Fabric is no longer positioning itself as “the future.” It is positioning itself as the platform enterprises can standardize on today.
Conclusion: Microsoft Fabric Is Built for Enterprise AI
FabCon Atlanta 2026 marked a clear inflection point.
With enterprise-grade networking, OneLake as a unified data estate, centralized OneLake security, and CI/CD-driven platform engineering, Microsoft Fabric has evolved into a complete enterprise data and AI platform.
Not a collection of tools. Not an analytics add-on.
But a foundation for responsible, scalable AI.
And now that most of these capabilities are generally available, the conversation changes from:
“Is Fabric ready?”
To the only question that still matters:
“How fast can we adopt it responsibly?
This blog focused deliberately on the platform foundations of Microsoft Fabric. FabCon Atlanta 2026 included many more announcements and deep dives that go beyond the scope of this post.
For the complete set of updates, sessions, and demos, watch the full recording here:
In today's world, data is the key to success for businesses. The more data a business has, the better it can make decisions and stay ahead of its competitors. However, data is not always easy to come by, and many businesses struggle with finding and accessing the data they need. This is where Microsoft Purview comes in.
Benefits
There are several benefits for data sharing in Microsoft Purview:
Safe time and resources from the business
Share data, Businesses can control who has access to their data
Secure, Businesses can control who has access to their data
Data sharing scenarios
Microsoft Purview Data Sharing can help with various data sharing scenarios, including:
Collaborate with external business partners while maintaining data security in your own environment.
Outsource data transformation and processing to third party ISVs or data aggregators by sharing raw data and receiving normalized data and analytics results back.
Automate sharing of big data (for example: IoT data, scientific data, satellite and surveillance images or videos, financial market data) in near real time and without data duplication.
Share data between different departments within the organization.
In place Data Sharing/Receiving in Microsoft Purview
Currently in Preview
Requirements:
Or do we need to say current limitations:
Supported Azure Regions: Canada Central, Canada East, UK South, UK West, Australia East, Japan East, Korea South, and South Africa North
Performance: Standard
Redundancy Options: LRS, GRS, RA-GRS
Storage Accounts: ADLS Gen2 or Blob Storage accounts
Source and Target storage account must be in the same region, this can be different from your Purview Account
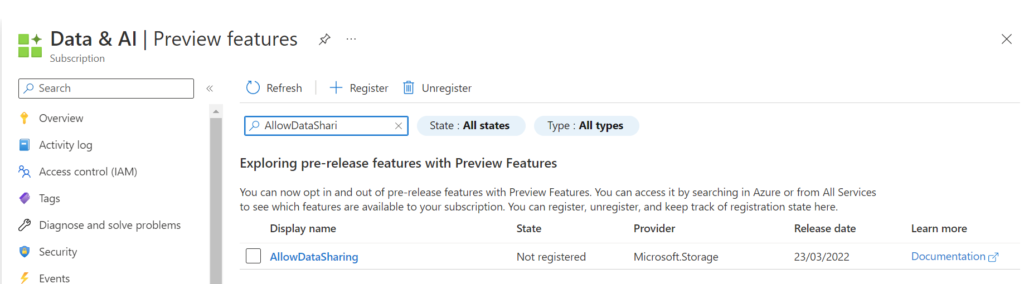
Before we can start we need to register the AllowDataSharing feature on the subscription.
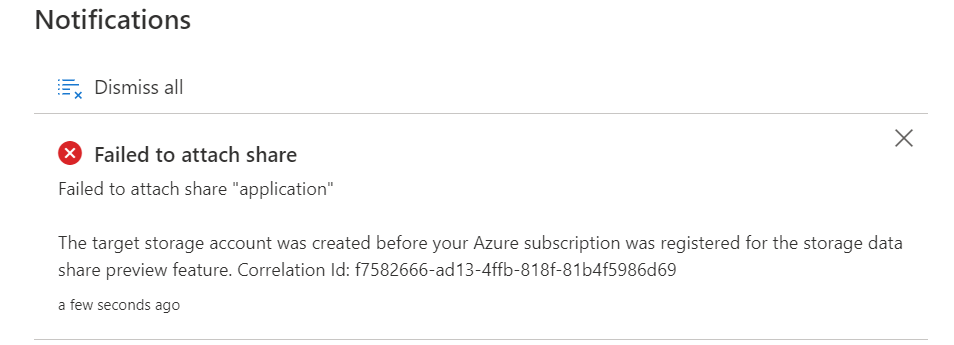
Attention
Only storage accounts registered after registration will work. If you did the registration after the storage account creation you will receive the following error message upon creation of the data share:
Create Share
To create a Data Share you must have the Microsoft Purview Collection Role, Data Share Contributors, assigned.
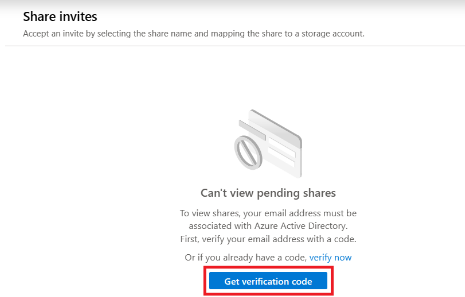
The first time you will start using Data Sharing and you're a Guest user, your account must first be associated with the Azure Active Directory.
You will receive a email with code, copy/paste the code before you continue.
To enable a data Share, select the Azure Storage or Azure Data Lake Storage (ADLS) Gen 2 data asset you would like to share data from.
Click on Data Share.
Create a New Share. Specify a name and a description of share contents (optional). Then select Continue.
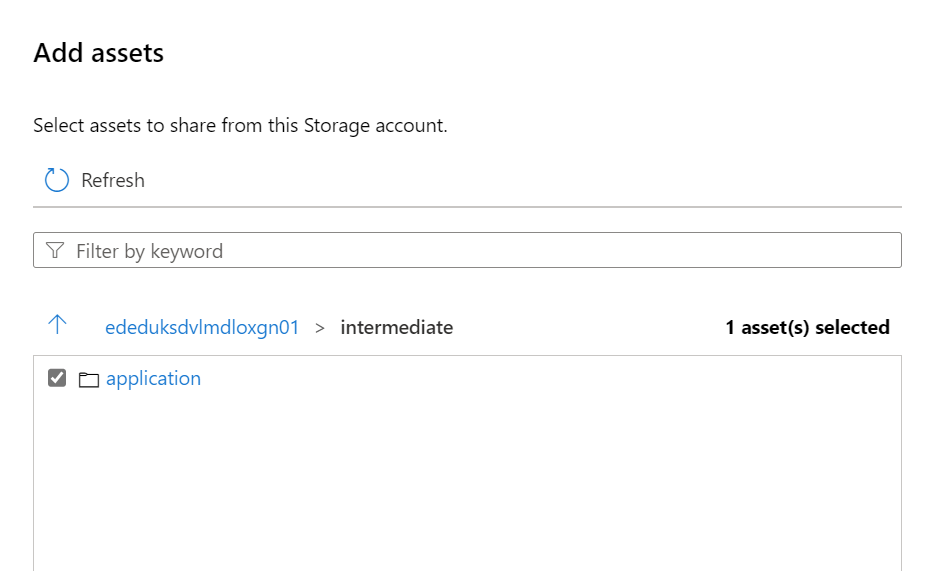
Search for the assets you want to Share and specify the Share name.
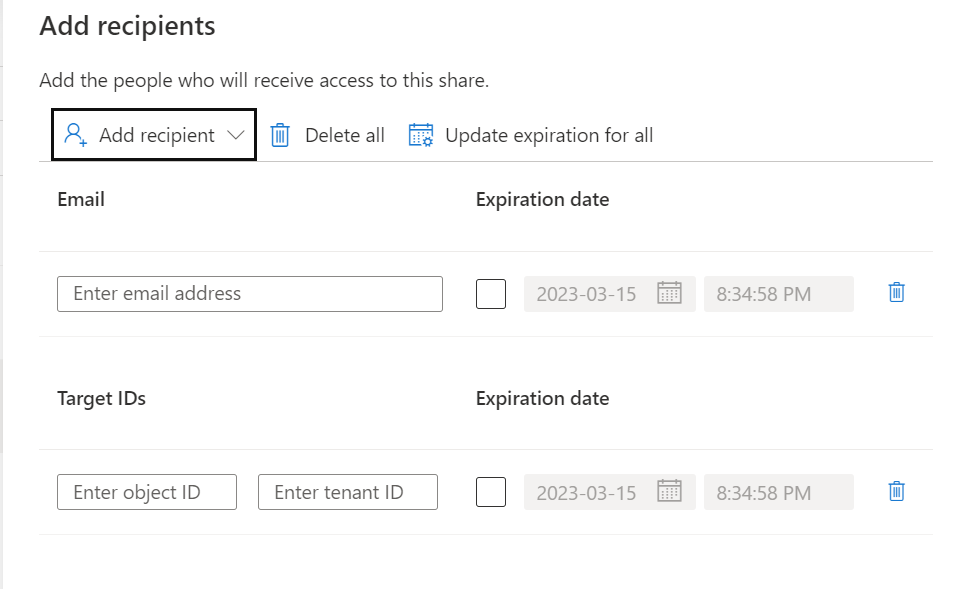
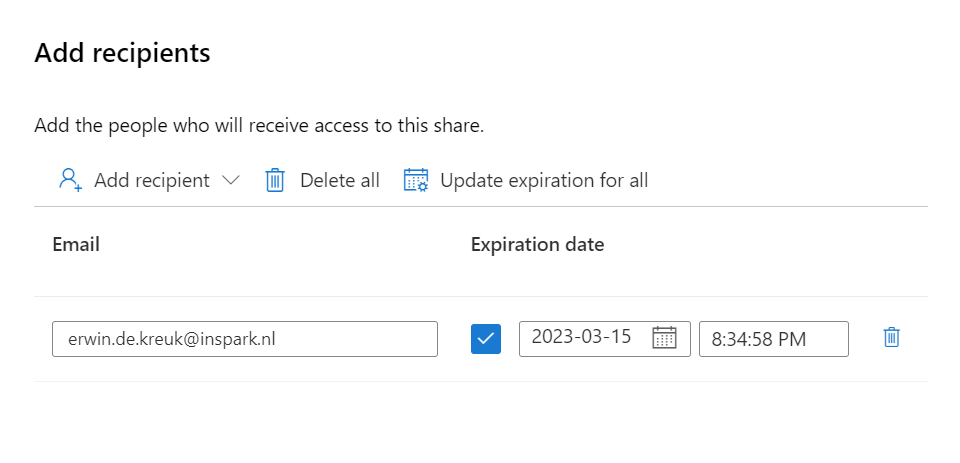
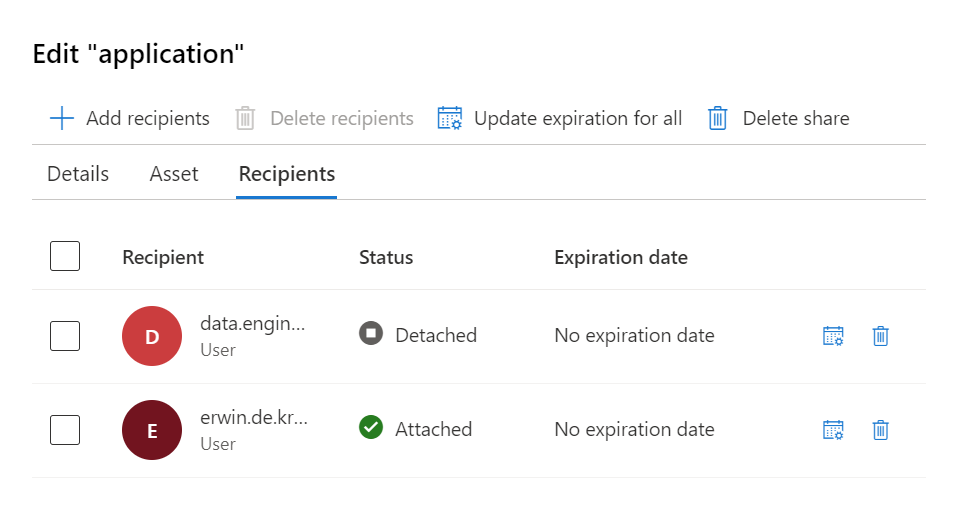
Add the Recipient, in this situation I've selected a user in a different tenant but you can also select in the same tenant, same subscription or different subscription.
Add the Recipient, in this situation I've selected a user in a different tenant and defined an expiration date of the share, the share will be terminated on this date.
Click on Create and Share, adding more users can be easily done afterwards.
The Share is created, The recipients of your share will receive an invitation and they can view the pending share in their Microsoft Purview account.
In Purview you will have an overview of all Shares you created:
Receive Share
Now we have setup the Sent Share, we're ready to receive the data. In this situation, it will be a different Purview account in a different Tenant.
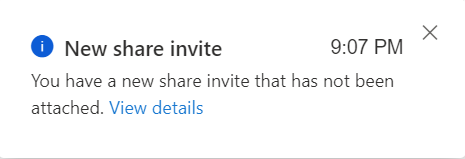
All invites which have been shared and not have attached can be found in the Share Invites tab.
A notification will also be send, that a new Invite has been received.
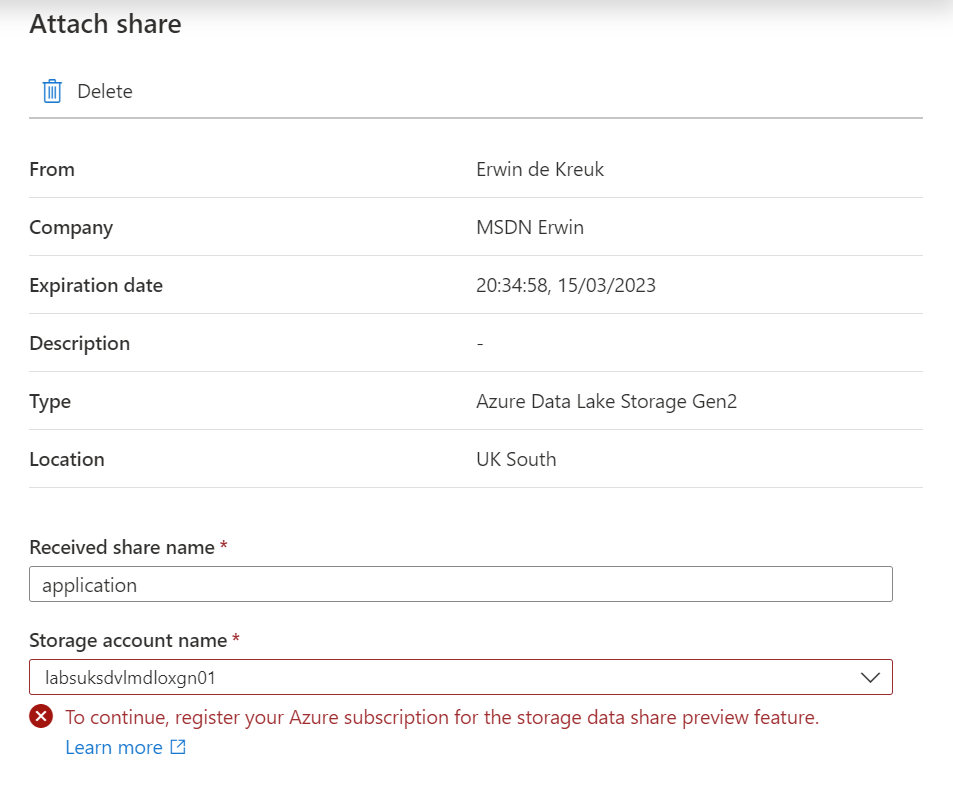
Click on Receive Share to attached to the correct Storage Account, make sure that the AllowDataSharing feature on the Azure Subscription has been registered, otherwise you will receive the message below.
Select the Storage account where you want to receive data or create a new storage.
Received share name: Leave as is or change it as you like it.
Path: New or existing container in Storage Account
Folder: The Folder where you want to receive the data
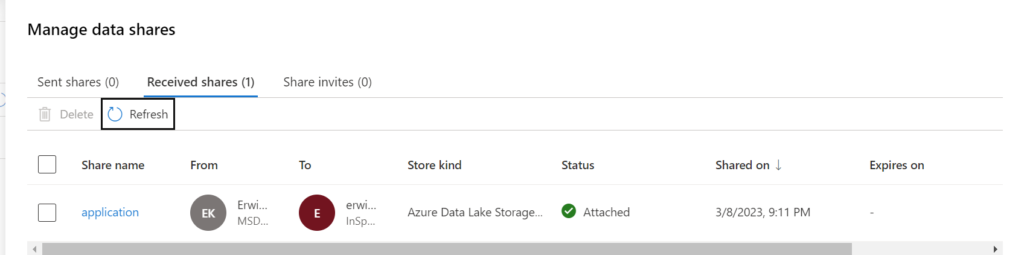
Attach the target to continue. When the storage account is attached you will see that on the Received Share overview.
You can now access the shared data in your storage account.
In the Purview account where we create the data Share we can also see that the data is attached.
Great to know, in the receive share the data is read-only, updated data in the sent share will be synced in real-time to the receive share.
In my next blogI will explain, how Microsoft Purview Data Sharing Lineage will work, just as a quick teaser. Have look in you data Assets, you will now find a new data asset:
Conclusion
Data sharing is a crucial component of modern business, and Microsoft Purview makes it easy and secure. By sharing data within and across organizations, businesses can improve collaboration, save time and resources, and stay ahead of their competitors. If you're interested in learning more about Microsoft Purview and its data sharing capabilities, be sure to check it out!
If you want to know more on Data Share Lineage in Microsoft Purview you read my blogon that topic.
Like always, if you have any questions leave them in the comments.