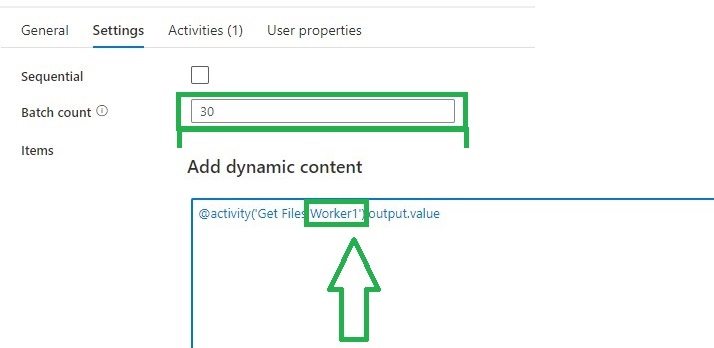
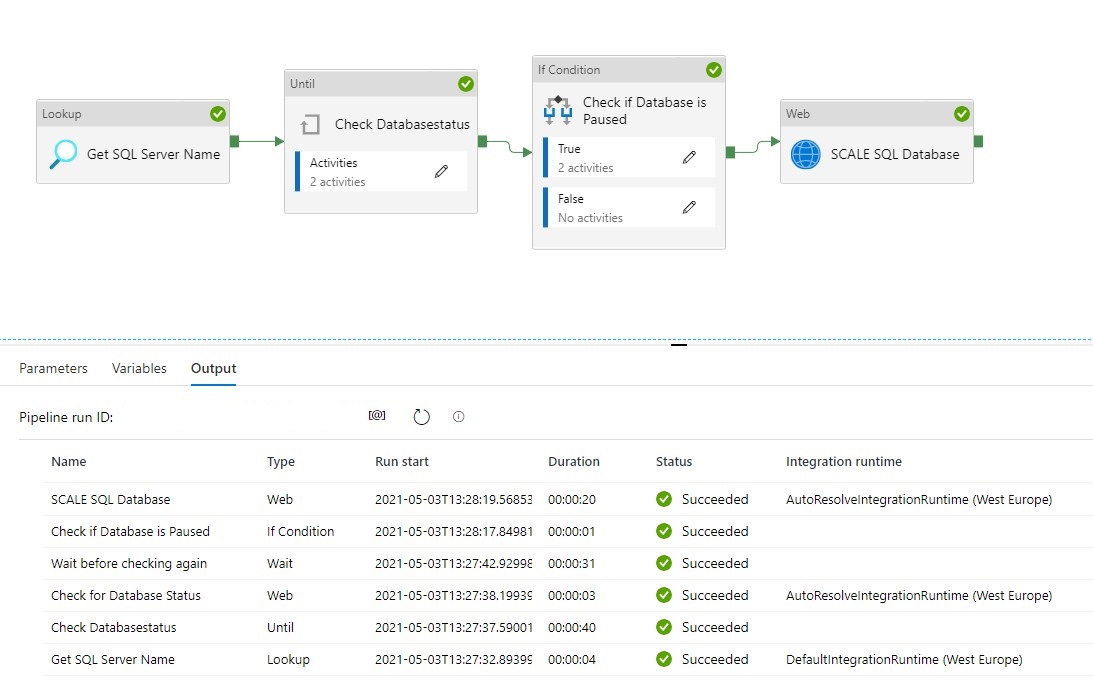
Azure Synapse Analytics overwrite live mode
Azure Synapse
Stale publish branch
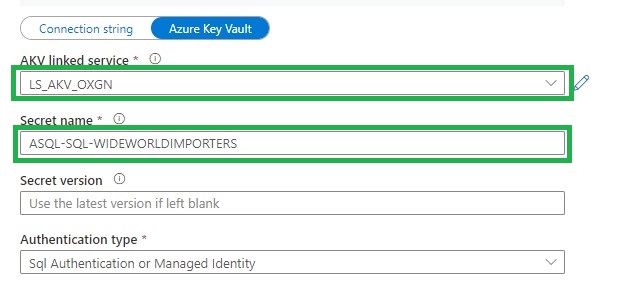
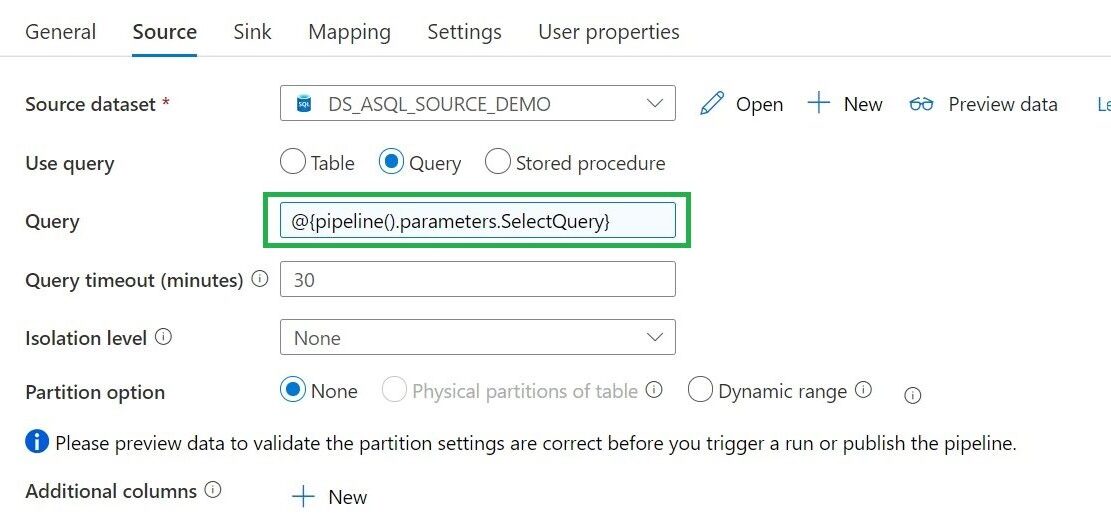
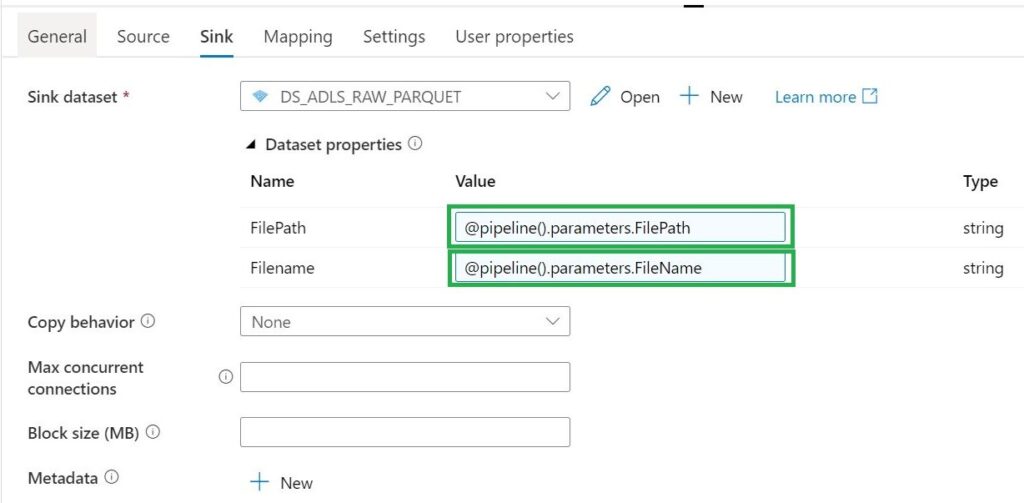
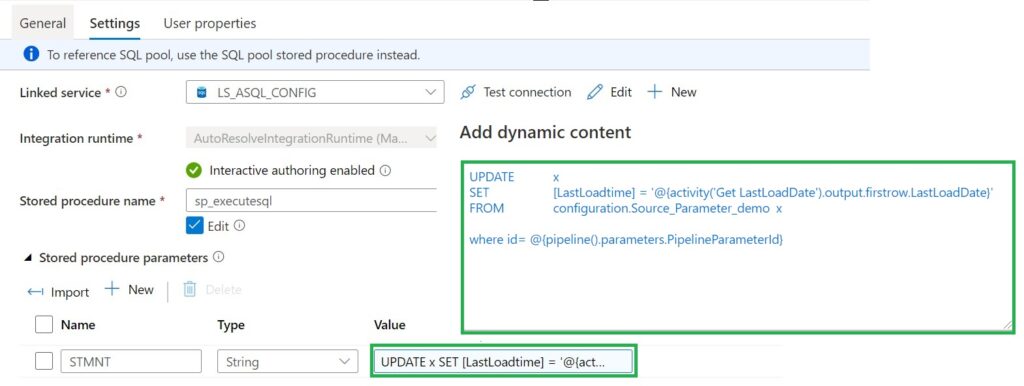
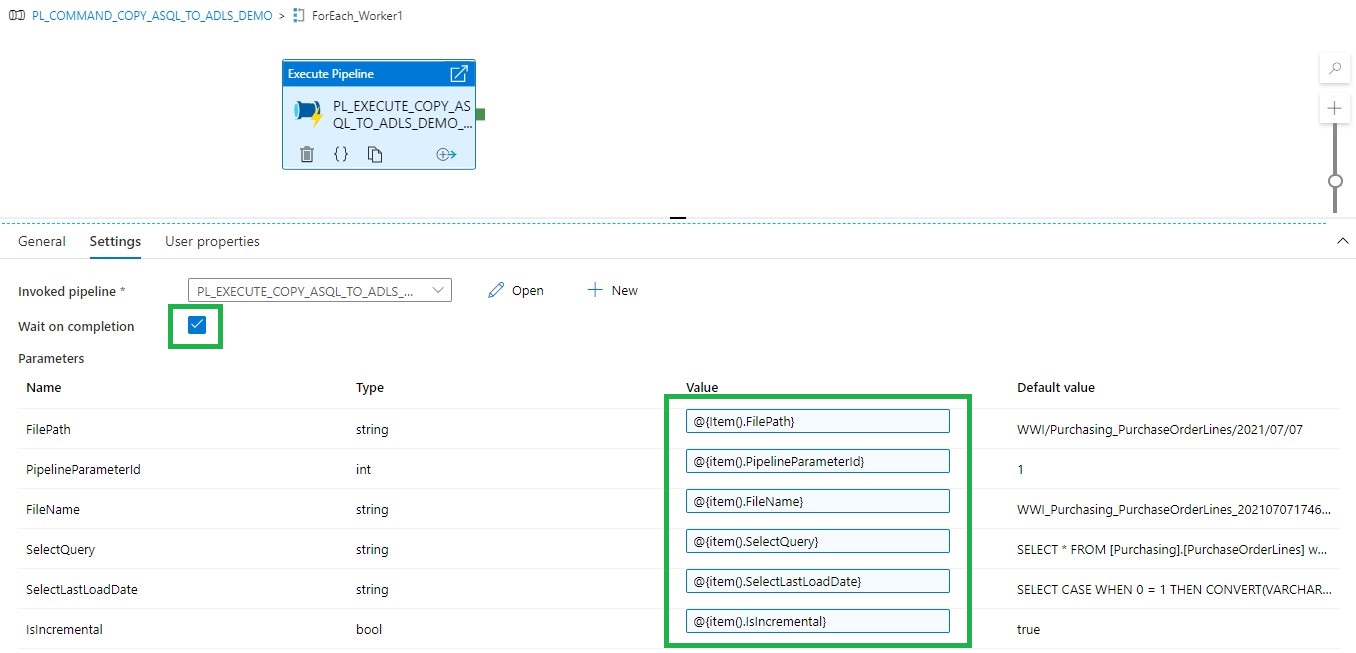
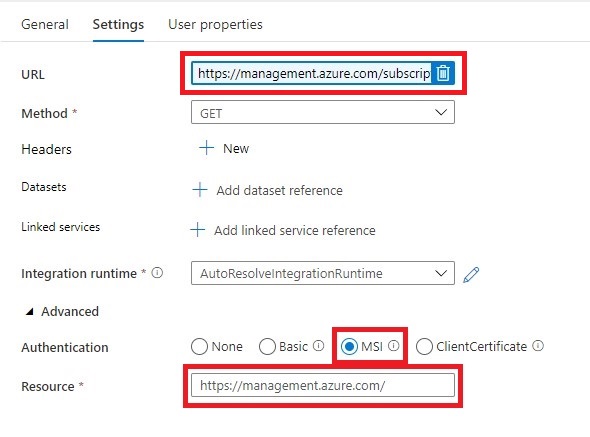
In Azure Synapse Analytics and Azure Data Factory is an new option available "Overwrite Live Mode", which can be found in the Management Hub-Git Configuration.
With this new option your can directly overwrite your Azure Synapse Analytics or Azure Data Factory Live mode code with the current Branch from your Azure Dev Ops.
It will use the Publish option to overwrite everything into your Azure Synapse Analytics or Azure Data Factory, so be careful with doing this. If you have a lot of code, the deployment time can take a while based on the size of the branch and the number of resources.
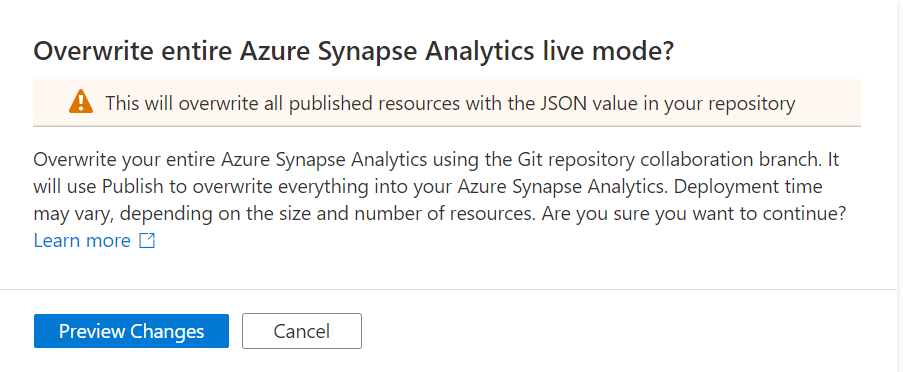
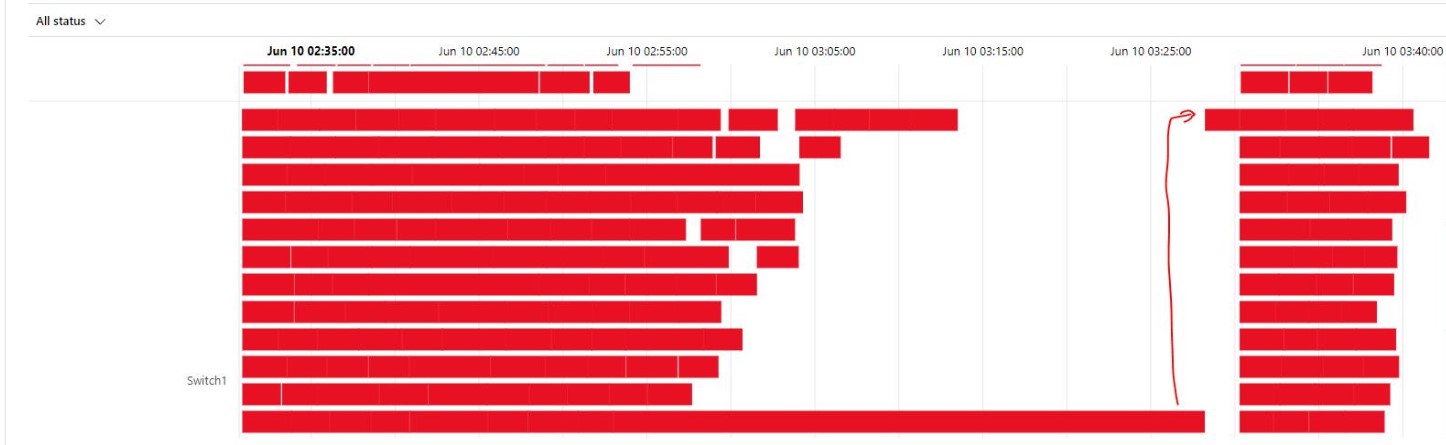
Once you click on Preview Changes you will see that all your code will be published. You need to confirm by clicking the Overwrite button.
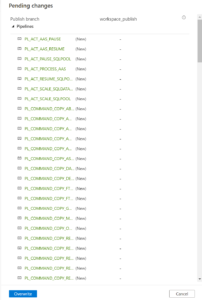
After you clicked on overwrite, it will start publishing.
Why?
Sometimes your Live Mode has a different code than your current Git Branch, especially when it comes to Linked Services, Managed Vnets and when using multiple Feature Branches. Incidentally, this is also the case if you link your code (Solution Templates) to your Azure Synapse Workspace from Dev Ops for the first time. Then it is possible that you will not get this code published because there are still dependencies, what I've seen mostly because the use of Azure Key Vault or different Integration Runtime setup. According to the documentation from Microsoft which you can find here they add the following examples:
- A user has multiple branches. In one feature branch, they deleted a linked service that isn't AKV associated (non-AKV linked services are published immediately regardless if they are in Git or not) and never merged the feature branch into the collaboration branch.
- A user modified the Synapse or data factory using the SDK or PowerShell
- A user moved all resources to a new branch and tried to publish for the first time. Linked services should be created manually when importing resources.
- A user uploads a non-AKV linked service or an Integration Runtime JSON file manually. They reference that resource from another resource such as a dataset, linked service, or pipeline. A non-AKV linked service created through the UX is published immediately because the credentials need to be encrypted. If you upload a dataset referencing that linked service and try to publish, the UX will allow it because it exists in the git environment. It will be rejected at publish time since it does not exist in the Synapse or data factory service.
If the publish branch is out of sync with your collaboration branch and contains out-of-date resources despite a recent publish, you can use the solution above.
Conclusion
I used to disconnect my Git configuration, make the changes in Live Mode, and reconnect Azure Dev Ops again and imported the resource to my current Branch. This solution makes it much easier and will safe you definitely a lot of time.
If you haven't yet linked your Azure Synapse Workspace to Azure Dev Ops, read how to do this in a previous Blog.
Hopefully this article has helped you a step further. As always, if you have any questions, leave them in the comments.
- Fabric Metadata Driven Framework July 2026 Release Notes

- Reassigning Microsoft Fabric Capacities in Bulk: Don’t Let an Expiring Trial Catch You by Surprise
- Bringing Column-Level Lineage from Microsoft Fabric to Microsoft Purview with FMD
- My first experience: Building a Fabric App
- Fabric Metadata Driven Framework update May 2026