Connect Azure Databricks to Microsoft Purview
Azure
Connect and Manage Azure Databricks in Microsoft Purview
This week the Purview team released a new feature, you’re now able to Connect and manage Azure Databricks in Microsoft Purview.
This new functionality is almost the same as the Hive Metastore connector which you could use earlier to scan an Azure Databricks Workspace. This new connector is an easier way to setup scanning for your Azure Databricks Workspace.
Note that this feature is currently in Public Preview.
The connector supports or will support:
- Extracting technical metadata including:
- Azure Databricks workspace.
- Hive server.
- Databases.
- Tables including the columns, foreign keys, unique constraints, and storage description.
- Views including the columns and storage description.
- Fetching relationship between external tables and Azure Data Lake Storage Gen2/Azure Blob assets.
- Fetching static lineage on assets relationships among tables and views.
Let’s have a look how to setup this connector, before you can start make sure you have the following Prerequisites in place:
- Microsoft Purview account with Data Source Administrator and Data Reader permissions.
- Self-Hosted Integration Runtime.
- Personal access token in Azure Data Bricks.
- Cluster in Azure Data Bricks.
Register the Azure Databricks Workspace
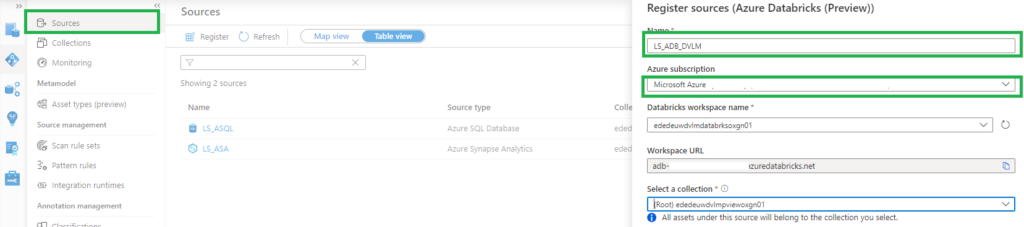
- Select Data Map on the left pane and select Sources.
- Select Register.
- In Register sources, select Azure Databricks and click on Continue.
- On the Register sources (Azure Databricks) screen, do the following:
- Enter a name that Microsoft Purview will list as the data source.
- Select the subscription and workspace that you want to scan from the dropdown list.
- Select a collection.
Setup the Integration Runtime
- Select Data Map on the left pane and select Integration Runtime.
- Click on New.
- Select the Self-Hosted.
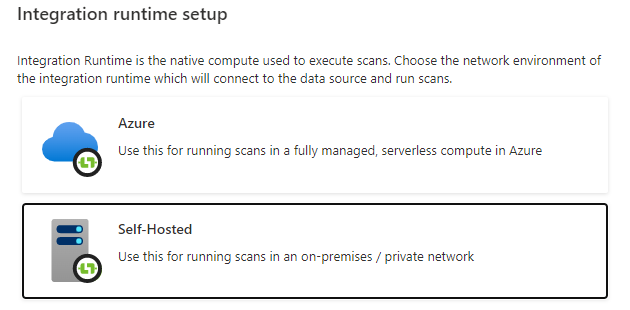
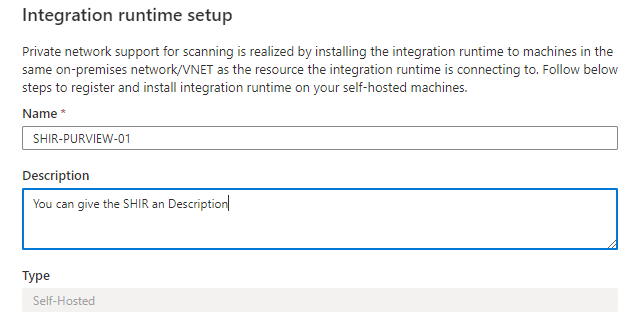
- Enter a name and description, click on create.
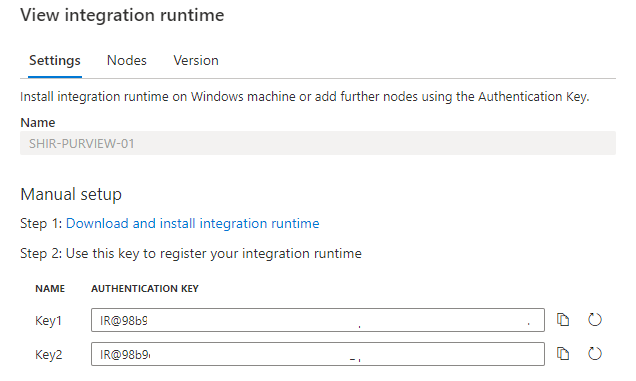
- Copy the authentication key.
Configure the Self-Hosted Integration Runtime
On an Virtual Machine in Azure:
- JDK 11, must be installed, not another version, I tried it with 17 and 19 this is not working. To download the JDK 11, you need to have an Oracle account.
- Visual C++ Redistributable for Visual Studio 2012 Update 4 must be installed.
- The Self-Hosted integration runtime, the minimal supported Self-Hosted Integration Runtime version is 5.20.8227.2. More information, on how to Create and configure a Self-Hosted integration runtime.
- After installing the SHIR paste the authentication key in the Gateway to start the communication. Wait before the communication start.
- Reboot your Virtual Machine to continue.
After rebooting, Select Data Map on the left pane and select Integration Runtime and check if the SHIR is running.

Setup the Scan
The last step to configure is the scan.
- Select Data Map on the left pane and select Sources and select the Azure Databricks you just created.
- Select New Scan.
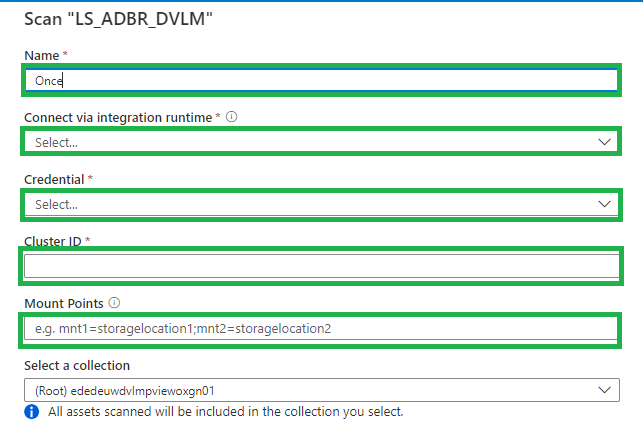
- Name, create a logical name for your scan. Weekly, Monthly, Once or a different name. TIP, add your clustername or id to the scanname. You need to create a scan for every cluster in an Azure Databricks workspace. This way you can see the difference between the clusters.
- Connect via IR, select the SHIR you just created.
- Credential, select the Personal Acces token, which is stored in de Azure KeyVault.
- Cluster ID, Specify the cluster ID that Microsoft Purview need to connect to, to perform the scan.
- Mount Point, if you have external storage manually mounted to Databricks, you provide the locations here. Use the following format /mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/.
- Maximum memory available: Specify the maximum memory available in GB to be used by scanning processes. If the field is left blank, 1 GB will be considered as a default value.
The default location of the cache in your VM is C:WindowsServiceProfilesDIAHostServiceAppDataLocalMicrosoftAzureDataCatalogCache. Unselect the checkbox if you want cache to be stored in a different location.
Click on continue.
Select the trigger you want. Click on save and run.
Check if the scan starts, be aware that the scan will trigger your Azure Databricks cluster to start.
Browse and search assets
Once the data is scanned you can browse and search the Metadata.
- Select Data Catalog on the left pane and select Browse Assets.
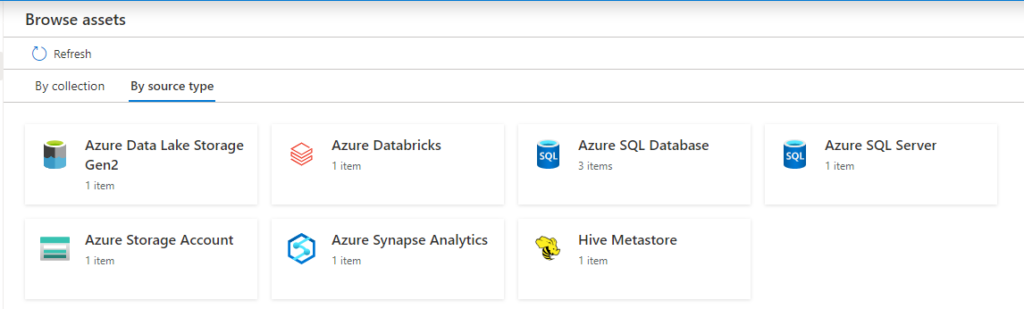
From the Databricks workspace asset, you can find the associated Hive Metastore.
Select the Azure Databricks and click on edit details on the right side.
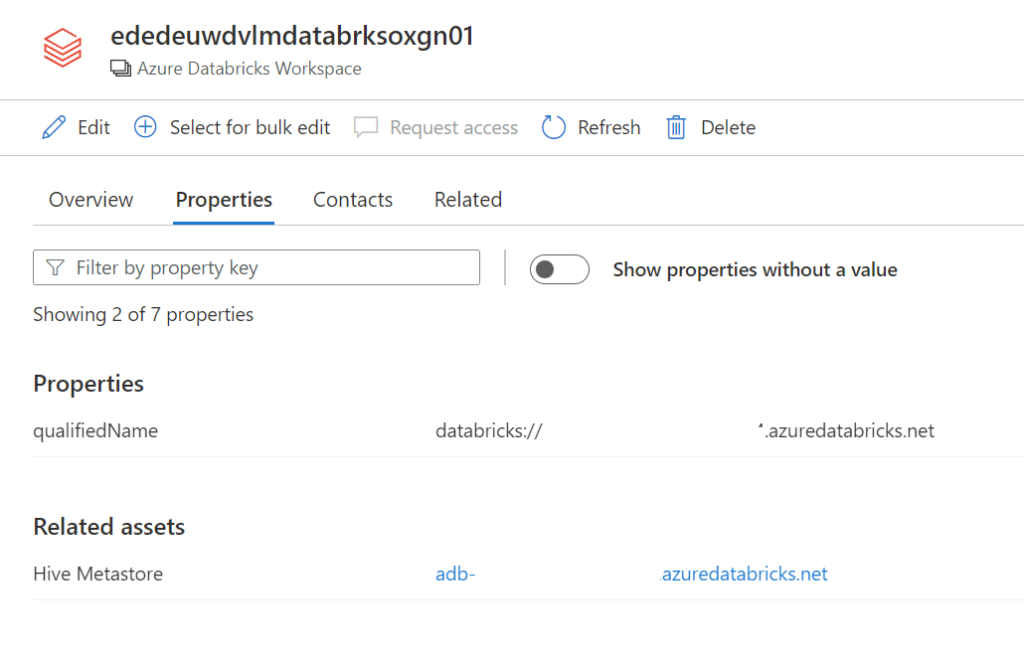
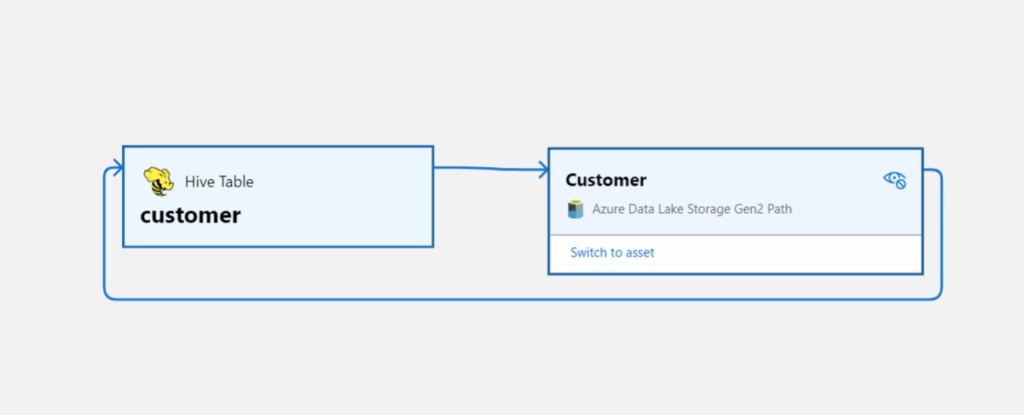
Click on Hive Metastore, on the Related tab you can see the Hive DB and the assets. Click on one of the assets to see the lineage when applicable.
Conclusion
The first steps towards a Native integration of Azure Databricks is now available in Microsoft Purview, but we're not there yet.
If you want to have a more extensive lineage and can read more details from the Notebooks execution including Delta Lake than, I advise you to use the
Azure Databricks to Purview Lineage Connector.
In the notes of this Solution Accelerators, is noted "With native models in Microsoft Purview for Azure Databricks, customers will get enriched experiences in lineage such as detailed transformations." So hopefully we can expect more in the future.
Be aware that lineage is available at the asset level not at column level, hopefully that will arrive soon.
In the notes of the above Solution Accelerators, is noted "With native models in Microsoft Purview for Azure Databricks, customers will get enriched experiences in lineage such as detailed transformations." So hopefully we can expect more in the future.
Like always in case you have questions, do not hesitate to contact me.
More details on above topic can be found here:
Connect to and manage Azure Databricks
Microsoft Purview Data Map supported data sources and file types