Stay up-to-date with the latest and most valuable content about Microsoft Fabric, all in one place! From insightful articles and tutorials to engaging videos and community blogs, you’ll find a treasure trove of resources to deepen your understanding.
Get ready for data enrichement in Microsoft Fabric
Azure OpenAI is fun and exciting and we can use it to do amazing stuff. In combination with Spark on Microsoft Fabric or Azure Synapse Analytics, we can transform and generate large amounts of text data and make use of OpenAI’s flexibility in defining the transformation. The SynapseML library that comes pre-installed on all Synapse Spark pools and Fabric workspaces includes an OpenAI module that allows you to perform OpenAI transformations on spark dataframes, enabling OpenAI at scale. Azure OpenAI is fun and exciting and we can use it to do amazing stuff. In combination with Spark on Microsoft Fabric or Azure Synapse Analytics, we can transform and generate large amounts of text data and make use of OpenAI’s flexibility in defining the transformation.
Together with Floris Berends we had a look into the possibilities and wrote the post below
Requirements
To run this example you need to have:
An Azure OpenAI service
A model deployment
A Microsoft Fabric workspace Alternatively, a Synapse Analytics workspace
A Spark Notebook
Extracting text fields from raw social media posts
Let’s say we are scraping social media posts and are interested in some of the details. Usually, scraping text fields results in some pretty messy data. For this example, we are using the Scikit-Learn newsgroups open dataset.
Set up a Spark Dataframe
In order to load the open dataset into a spark dataframe, we first load it into a pandas dataframe. Of course if you are using your own data, you can load the data from anywhere, as long as it fits into a spark dataframe
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
newsgroups = fetch_20newsgroups(subset="train", categories=['talk.politics.misc'])
pd_df = pd.DataFrame(newsgroups["data"], columns=["data"])
df = spark.createDataFrame(pd_df)
Set up our parameters
To prepare the OpenAI transformation, we need to provide the API with a number of connection and configuration parameters. These include the Azure OpenAI service name, the name of the model deployment, and a prompt that will specify our transformation. The parameters can be found in the Azure Portal, on your Azure OpenAI resource. If you have not yet deployed a model, do this now. Note that the prompt specifies what we want the model to do, but also specifies the format in which we want the model to respond. This is crucial in getting reliable results from the model and this is what enables us to use the transformation as part of a pipeline.
openai_service_name = "<YOUR SERVICE NAME>"
openai_deployment_name = "<YOUR DEPLOYMENT NAME>"
openai_key = "<YOUR SERVICE KEY>"
source_content_column = "data"
system_prompt = """
You will read the raw text of an e-mail and extract the senders e-mail
address and subject from the text. You will also list the topics of the email, provide a short one-sentence summary, and output the sentiment of the email. Ensure that the sentiment is one of the following: negative, neutral, positive.
Your response will be in the following format
{{
"EMAILADDRESS": "",
"SUBJECT": "",
"SUMMARY": "",
"SENTIMENT": "",
"TOPICS: []
}}
"""
Set up the prompt column
Because OpenAI needs a prompt in order to generate a completion, we need to setup a prompt column that includes both the instruction (system_prompt) we set up earlier and our data. The way that Azure OpenAI chat completions work, is that you can provide the ‘chat history’ as a message column. This column is what we will use as input for the transformation. Additionally, Azure OpenAI chat completion messages include a ‘role’ parameter. The role specifies who sent the message. In a normal chat interaction, there are 2 roles: the user and the assistant (i.e. the model). However, it is possible to provide a ‘system’ message that will instruct the model how to behave. We will use a ‘system’ message in order to instruct the model on how to transform our data. In order to do this, we need to set up the prompt column in the following way:
A message with the ‘system’ role and our instruction as content.
A message with the ‘user’ role and our data as content.
Now that we have the input dataframe with the data and prompt just how we want it, we can set up the call to the Azure OpenAI API. Note that Spark will not immediately execute the transformation, but will simply setup the plan for the dataframe. The API will only be called when we actually need the data (e.g. when we save or display the dataframe).
The OpenAIChatCompletion mehthod simply puts the completion results into the output column, but we want to have the results in separate columns. Before we can do this we need to define the output schema.
output_columns = "EMAILADDRESS,SUBJECT,SUMMARY,SENTIMENT,TOPICS"
prompt_schema = StructType(
[StructField(col, StringType(), True)
for col in output_columns.split(",")
])
df_result = completion.transform(df.limit(10)).withColumn(
"response",
F.from_json(
F.col("output.choices.message.content").getItem(0)
,prompt_schema)
).select("response.*","error")
Displaying and Verifying the results
There are a number of things that can go wrong. For any row, errors returned by the API will be put into the error column that you provided by .setErrorCol. We can display the dataframe to inspect the results:
display(df_result)
Final
It might seem that this setup is so versatile that you can use it to apply any transformation you desire on any column in any dataset. Although this might not be far from the truth, there are a couple of things you need to consider:
Cost: Azure OpenAI transformations are more expensive then those that do not rely on external APIs (e.g. Spark Native transformation like map(), flatten(), explode(), or using regular expressions and the like).
Complexity: This example applies a transformation with a simple output schema. It might very well be the case that asking a LLM to output data in a very complex schema will not turn out well.
Language: This example applies a transformation that is primarily a language based transformation: extracting and summarizing information that is available as natural language. Using LLMs to apply math-based, logic-based, or code-based transformations might not show reliable results.
The main take-away is that using Azure OpenAI to transform text-fields though natural language operations like summarization, description and extraction can be done fast and reliable. We are looking forward to seeing where this technology will take us.
I got some questions from customers that didn’t know how to enable Microsoft Fabric and that they only see Power BI Items and not the new announced Experiences. In this short blog I will explain how you can easily enable Microsoft Fabric.
How to enable Fabric
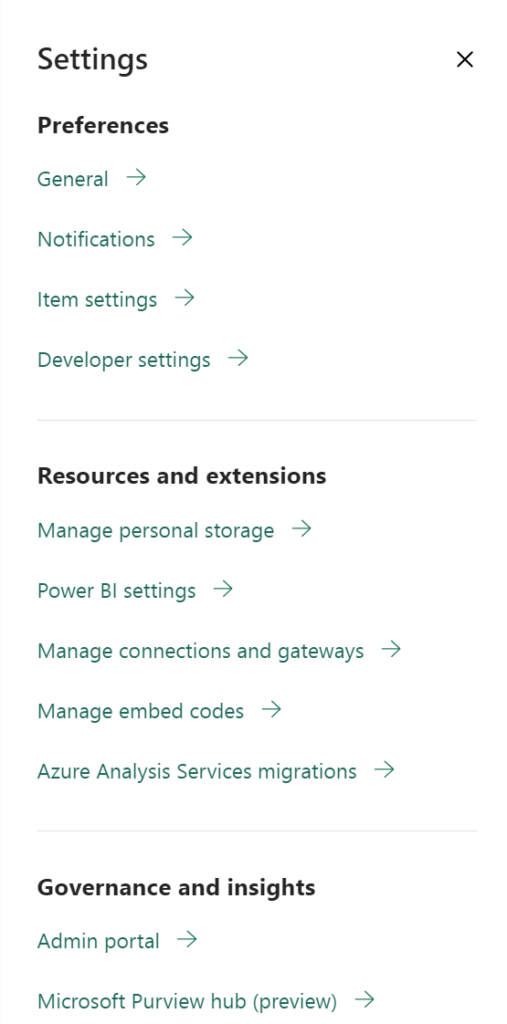
If you want to try Fabric in your tenant, you need to enable the Fabric features in your Power BI admin portal.
To do, go to https://app.powerbi.com/.
Note: You must be an Power BI administrator
Please note that Microsoft FabricCapacity(Trial)or Power BI Premium Capacity is required to get started with Microsoft Fabric.
Open the Microsoft Fabric admin portal.
By default, Microsoft Fabric is disabled (if you do not change the setting, it will be set to ON after July 1st 2023).
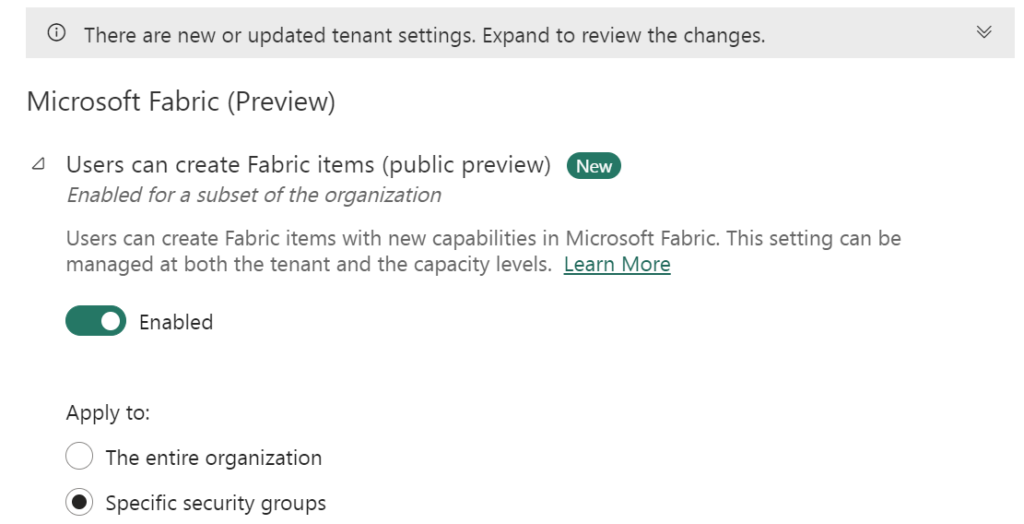
You enable Microsoft Fabric for the whole organization or you can just start with a small group(Specify Security Groups). My advice is to start with a small group. Microsoft Fabric is in Public Preview and not ready for Production Environments.
It will take up to 15 minutes to deploy these setting, mostly much faster. After that the new experiences will be available.
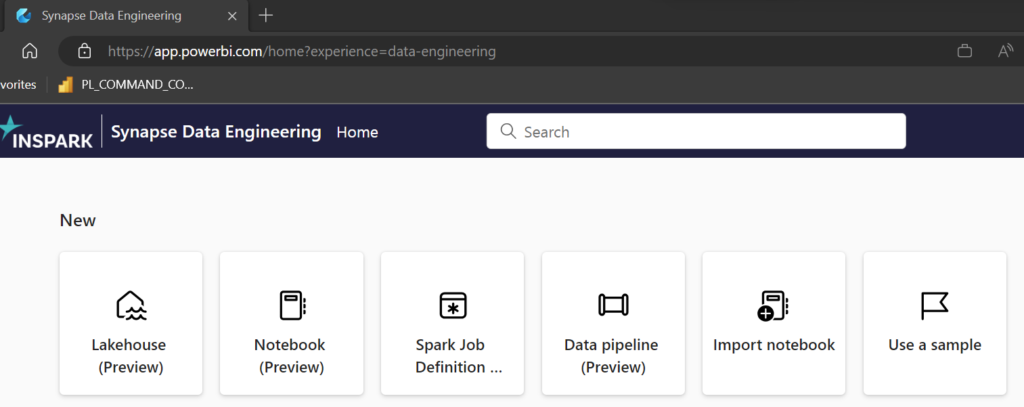
Select Data Engineering
In the top of the page you can directly, see which experience you use.
In this case Synapse Data Engineering Experience, check out the logo on the left side and the text behind home?experience
Start Trial
Have a look to this page how easily it is to get started with a free TrialFabric (preview)
Guy in the Cube
You also watch the video, who Adam Saxton created:
Documentation
If you have any questions, I’d love to hear them. More information about Microsoft Fabric can be found at my Content Hub:
Since the first of June 2023, we can create Fabric capacities in Azure. This are currently the Pay as You go pricing, later this year the Azure Reservation will follow. OneLake storage pricing is comparable to Azure ADLS (Azure Data Lake Storage) pricing and is not included in the price below. These prices are prices in the West-Europe region, prices can be different across regions.
Note: As you can see, the F1024 and F2028 are not having the correct prices, it should be 2 or 4 x F512. The error is already is report to the Fabric Team.
Microsoft Fabric Capacity is a distinct pool of resources allocated to Microsoft Fabric that resides on a tenant. The size of the capacity determines the amount of computation power your organization gets.
Microsoft Fabric has an array of capacities that you can buy. The capacities are split into SKU's. Each SKU provides a different amount of computing power, measured by its Capacity Unit (CU) value.
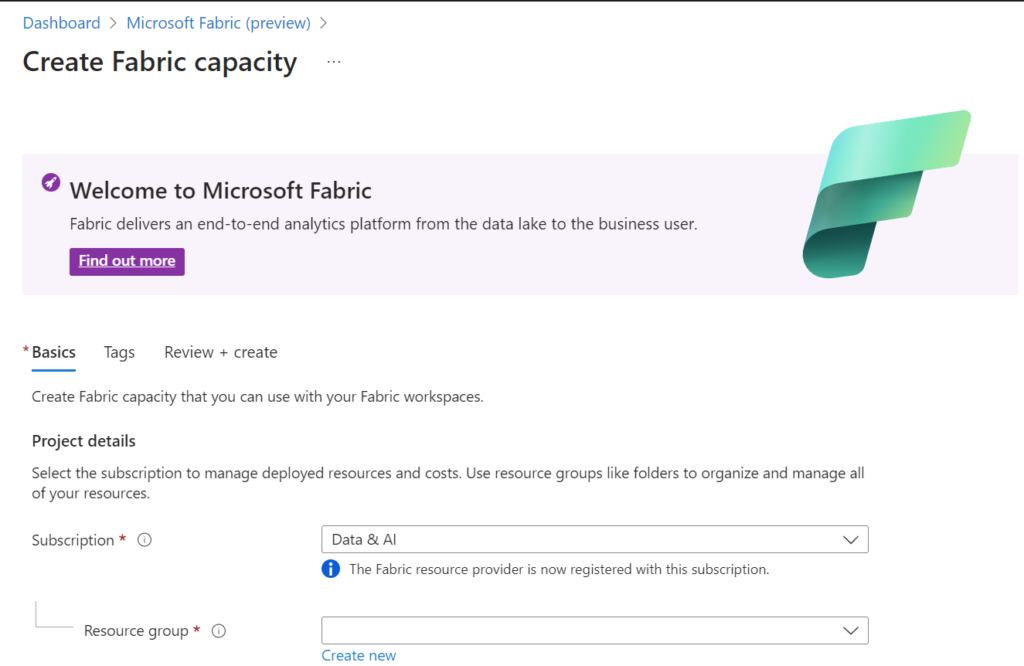
Creating Fabric Capacity in Azure
Search for the Fabric Capacity in the Azure Marketplace.
Select the appropriate Subscription and resource group. You can move the Fabric capacity to another Resource Group later if needed.
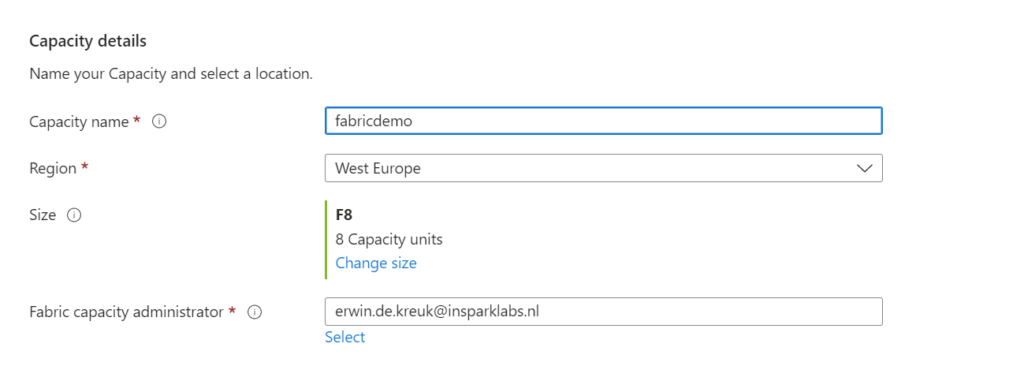
Provide a name for the capacity.
Define the region for the capacity.
Choose the desired size, starting from F2. F64 is equivalent to a Power BI Premium capacity. You can learn more on this page.
Assign a Fabric capacity Administrator.
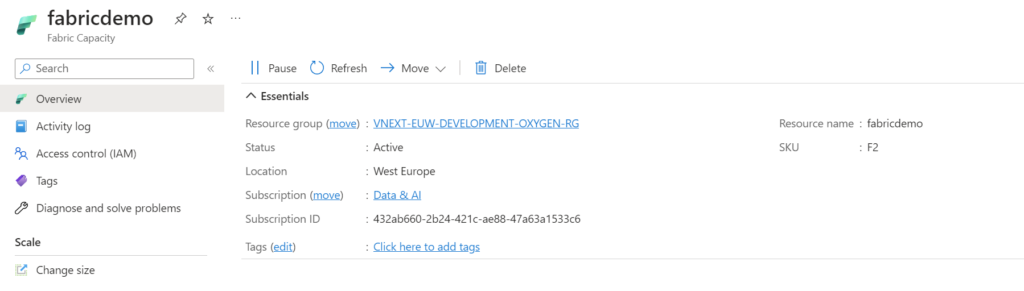
Click on "Create" to initiate the capacity creation process. Once created, you will see the relevant information on the screen.
Assign capacity in Microsoft Fabric
After creating the Fabric capacity, you need to assign it to a Workspace by following these steps:
Open the Microsoft Fabric admin portal.
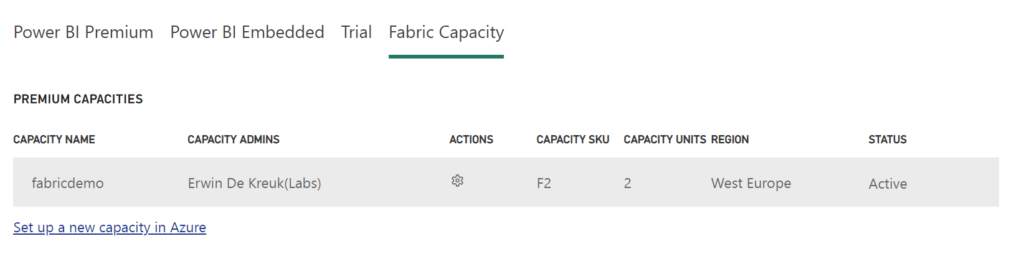
Select the capacity option on the right side.
Locate the recently created capacity in the list.
Assign capacity to a Workspace
The last step is to assign the capacity to a Workspace.
On the Workspace level, click on settings.
Go to the Premium tab and select the Fabric capacity.
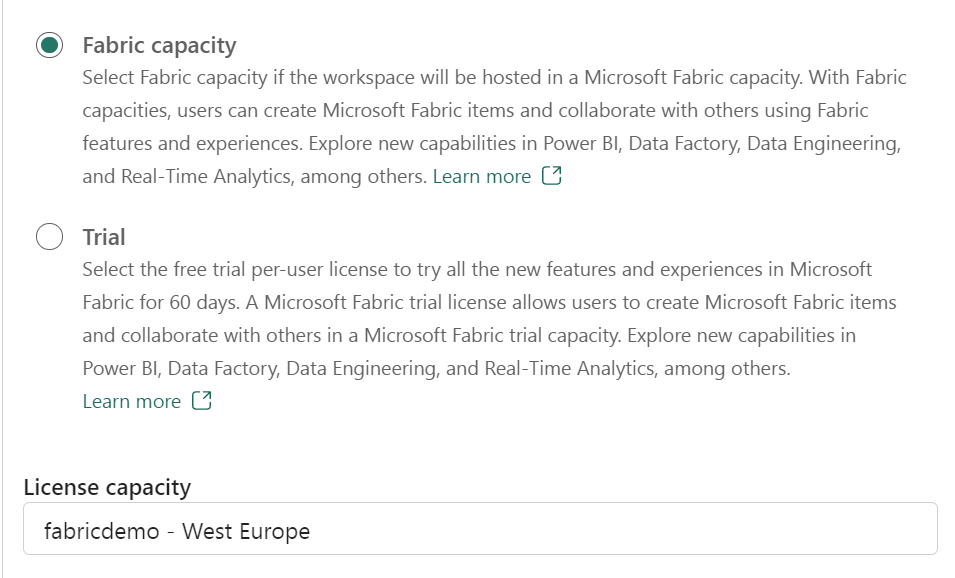
Define the correct License capacity for the Fabric capacity.
Select the Fabric Capacity and define the correct License capacity to it. That's all, you are now using the new capacity.
Capacity Pause/Resume
With the Fabric capacity set up, you can take advantage of the Pause/Resume feature, which allows you to temporarily halt and resume the capacity, making it useful for development and testing purposes. However, please note that this option will not work if you purchase Azure Reservation in the future.
Microsoft Fabric app
To monitor usage and related to Microsoft Fabric capacities, you can use the Microsoft Fabric utilization and metrics app.
To install the Microsoft Fabric Capacity Metrics app for the first time, follow these steps:
When prompted, sign in to AppSource using your Microsoft account and complete the registration screen. The app takes you to Microsoft Fabric to complete the process. Select Install to continue.
In the Install this Power BI app window, select Install.
Wait a few seconds for the app to install.
It's a pretty simple process to set it up.
Documentation
If you have any questions, I'd love to hear them. More information about Microsoft Fabric can be found at:
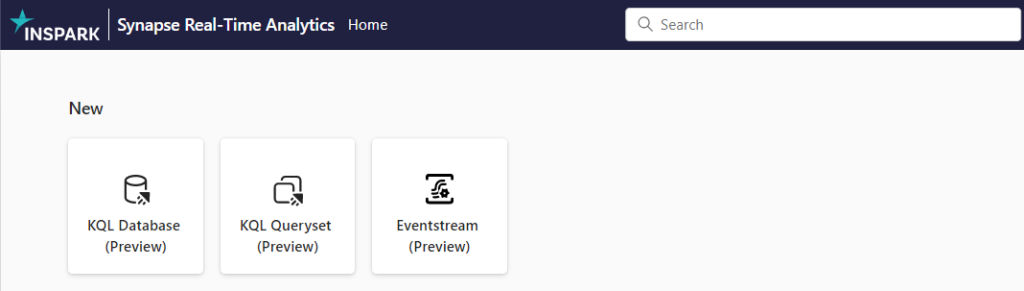
Connecting Azure Event Hubs with Eventstream in Microsoft Fabric
In my previous blog I did give you an introduction of the possibilities of Real-Time Analytics in Microsoft Fabric.
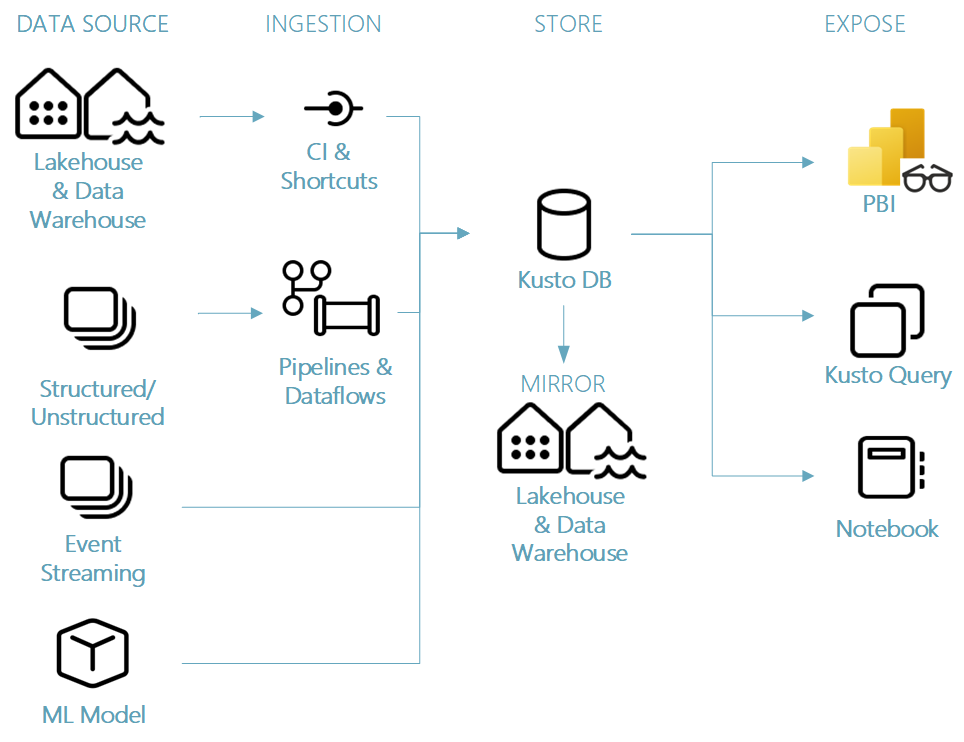
In this blog we will have a closer look into how we can connect data from one of our existing Azure Event Hubs.
Looking to the above picture, you see an end to end workflow for a Real-Time Analytics scenario. We can directly see which Fabric Artifact we need to use to build the solution. To build the complete solution below took me maximum 20 minutes,.
Loading data from Azure Event Hubs to Lakehouse
Requirements:
An existing Azure Event Hub.
New consumer group(never you use an existing). If you use an existing consumer group then it can happen that the event hub stop sending messages to your existing environment.
Fabric Workspace
Note:
Adding a consumer group is not available in the Basic tier but only in the Standaard Tier.
Creating a Shared Access Policy on the Event Hub
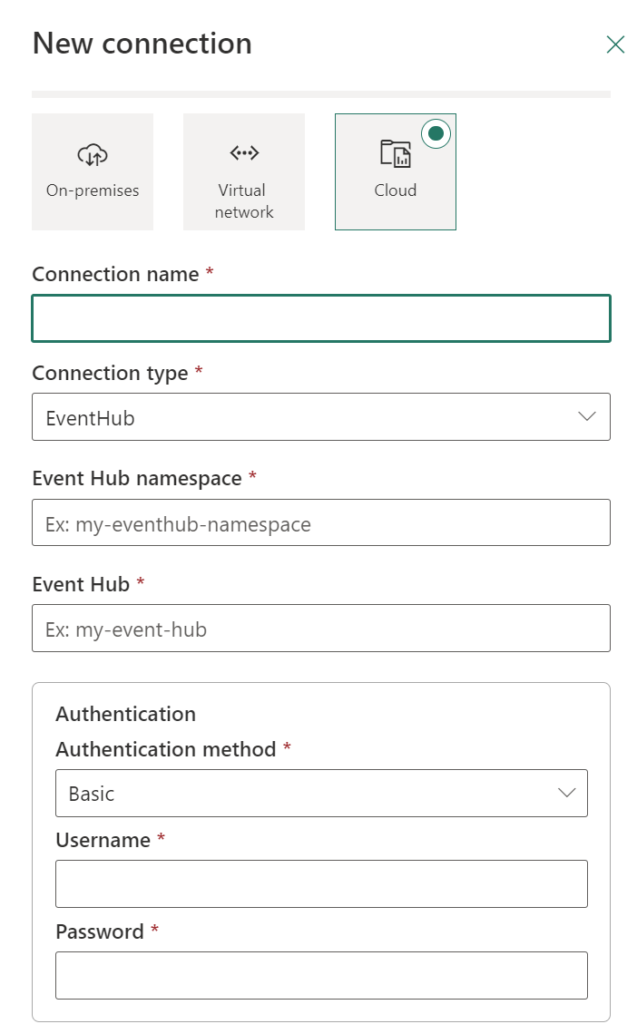
Create a new Shared Access Policy on the Event Hub, with the manage option enabled.
Note down the SAS Policy name and the Primary Key. We will need this later to setup the Connection in Microsoft Fabric.
Create a Data Connection in Microsoft Fabric
In the menu bar(top right) open the settings toggle and open the Manage Connection option.
Make sure you have a Microsoft Fabric or Power BI Premium capacity assigned to this workspace.
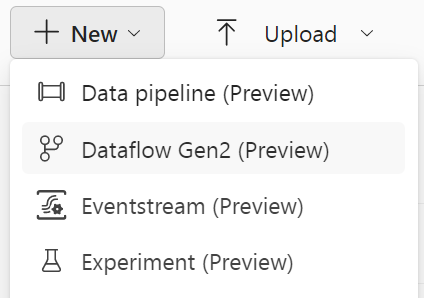
Create Eventstream in Microoft Fabric
Within our Fabric Workspace, select NEW on the left upper corner and select Eventstream.
Define a name for the Evenstream and click on create.
This can take a couple of minutes to setup, but don’t worry there are a lot of things happening in the background. Microsoft Fabric is a SaaS application so things needs to be deployed for you.
The great advantage for you, things will much easier to setup.
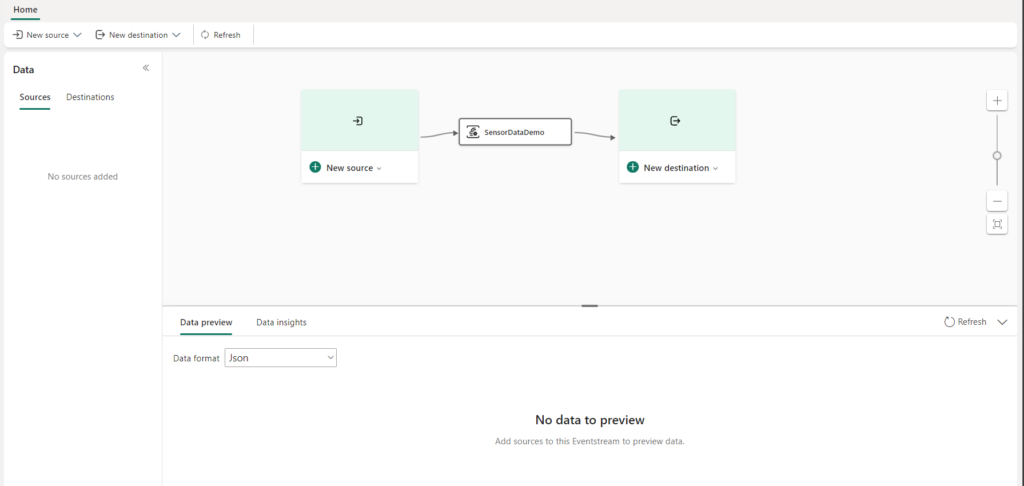
So once everything is ready you will see this new screen:
Create the Eventstream Source
Next step is to connect our Source, in this case the connection to the Event Hub.
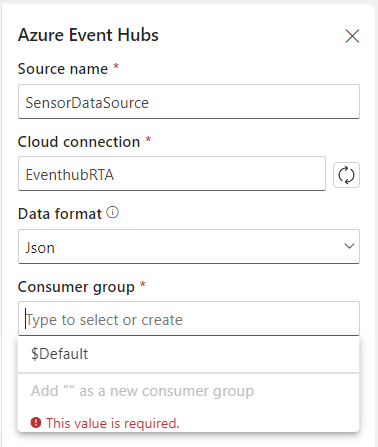
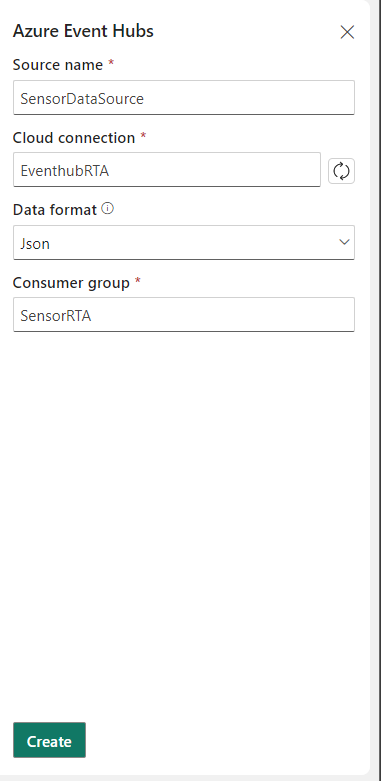
Select the Azure Event Hubs, a new pane will open.
Source name
Define a name for your source, you can use the name of the Event Hub or a custom name
Cloud Connection
Select the connection you’ve created in the beginning of this blog
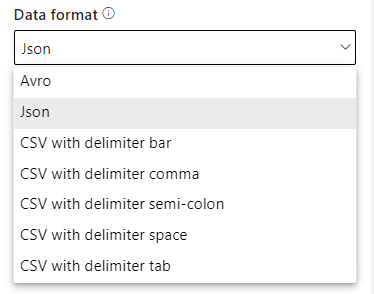
Data Format
Define the correct format based on your Event Stream
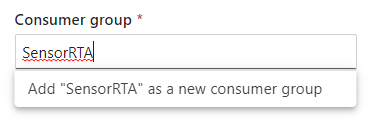
Consumper group
You can select a group you have a created in the beginning of this blog. Or you create a new one as well.
Note: Never you use an existing Consumer Group, because your current application connected to this Consumer Group will stop receiving data.
Once all the required field are filled in, click on Create. Now the source of your Eventstream will be created.
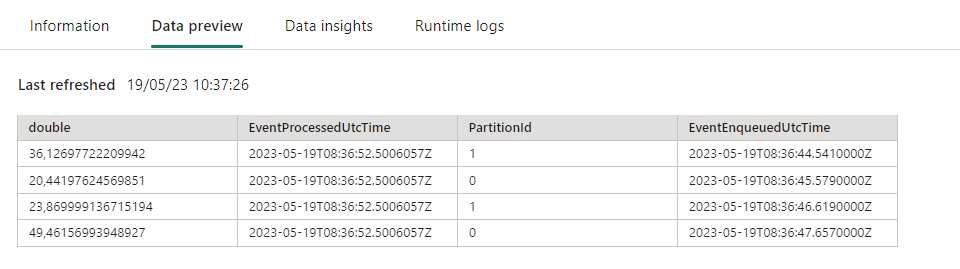
After the connection is setup successfully you can click on Data Preview, to see what kind of data is coming in and if this is the correct data.
If you data is not shown the correct way, you can change data format to csv or avro.
Destination
One of our last steps in our configuration is to setup the destination for the Eventstream.
In this blog we will use a Lakehouse(more destination are available), so that we can store our data and use it in a later stadium to build reports on top of the data.
Lakehouse
You can choose if you want to create a new Lakehouse or use an existing one.
If you do not have created a Lakehouse, you need to create one.
Select in left bottom corner, the option Data Engineering.
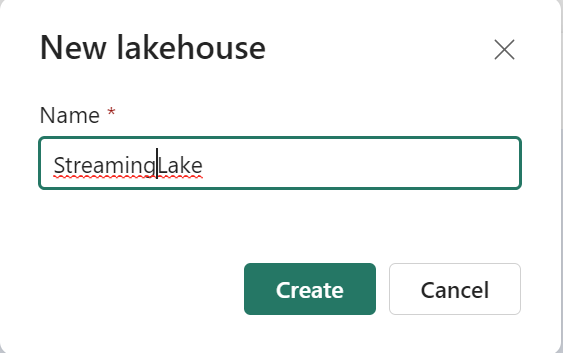
Create a New Lakehouse, define a name and click on create.
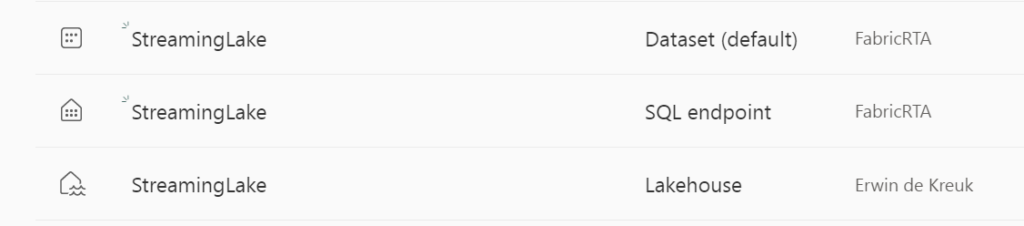
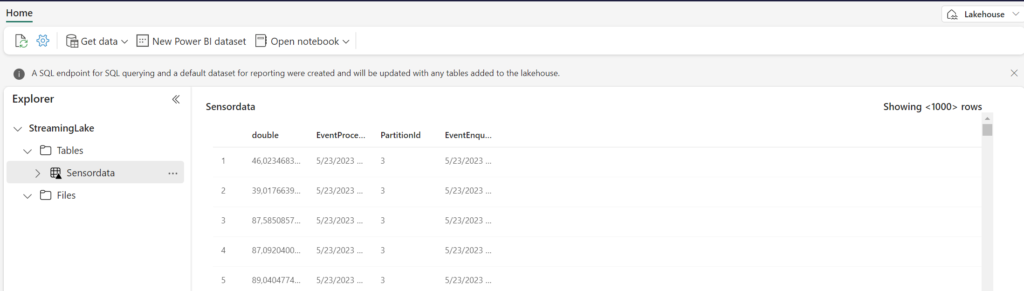
After creating a Lakehouse, you will see that Automatically a Dataset and a SQL Endpoint are created by default. How easy is that!
Create the Eventstream Destination
Create Lakehouse as Eventstream Destination
A new windows will open were we can configure the Lakehouse connection/destination.
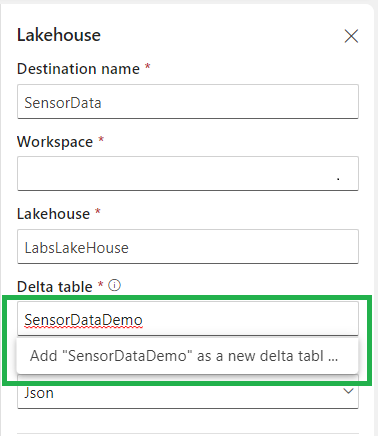
Destination Name
The name of the destination
Workspace
The workspace were you’re Lakehouse is located
Lakehouse
The Lakehouse you want to use(you can have more than 1 in the same workspace)
Delta table
The Delta Table were you want to store the data, you can also create a new table from here.
Data format
Mostly the same format as the data you added to in Source
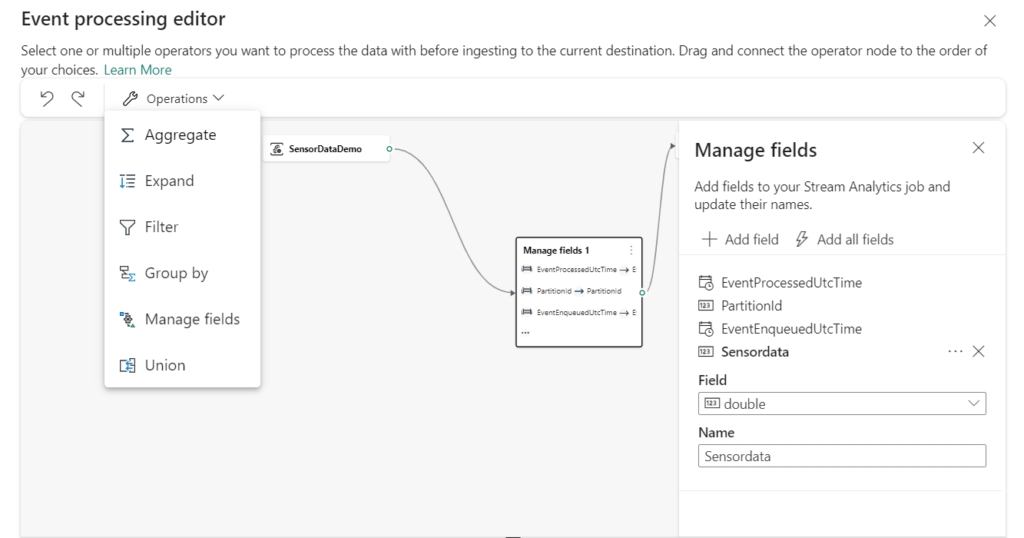
Event Processing
Before you create the destination, you can transform and preview the data that is being ingested for the destination with the Event Processor. The event processor editor is a no-code experience that provides you with the drag and drop experience to design the event data processing logic.
As you can see there’re a lot of operations/transformation possible to transform your data in a correct way, renaming a field is a matter of seconds with a no-code experience.
The last step is to create the destination. It is just as easy as it is, click on Create.
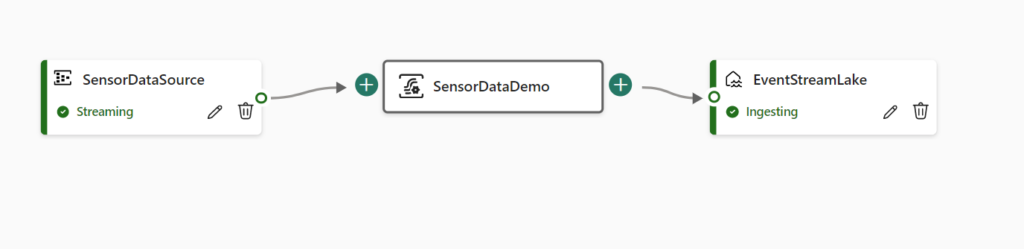
The Eventstream is ready, Source is streaming data and the destination is Ingesting data.
Navigate to your Lakehouse to verify the ingested data.
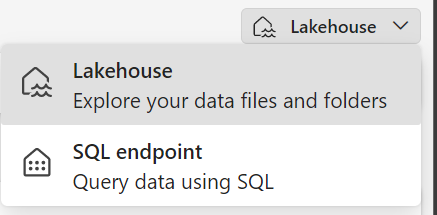
If you prefer to verify with a TSQL command, you can easily switch to a SQL Endpoint mode, which is located in the upper right corner.
And now you can run any type of query you want.
Next Steps
Build Power BI report with the ingested eventdata in the Lakehouse. As mentioned before a default dataset is already created.
In my next blog I will explain how we can start using the KQL database as a destination, so stay tuned.
Documentation
Click below to read more about Microsoft Fabric and Real-Time Analytics.