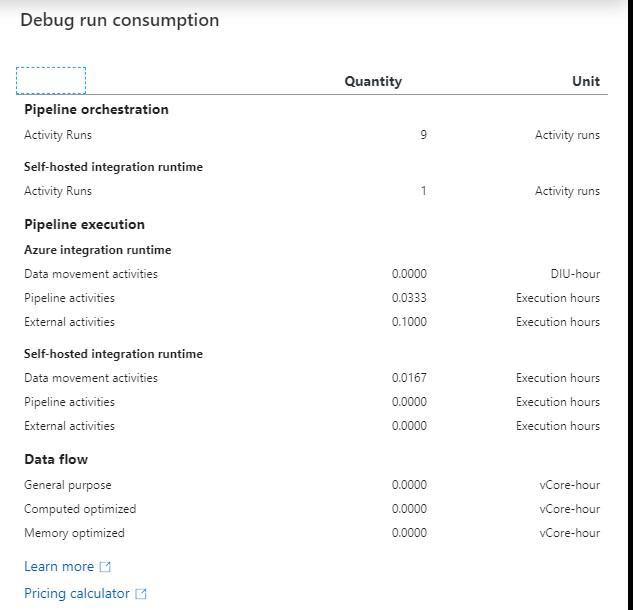
Create an Azure Synapse Analytics Apache Spark Pool
Erwin
Adding a new Apache Spark Pool
Go to your Azure Synapse Analytics Workspace in de Azure Portal and add a new Apache Spark Pool.

Or go to the Management Tab in your Azure Synapse Analytics Workspace and add a new Apache Spark Pool.

Create an Apache Spark Pool
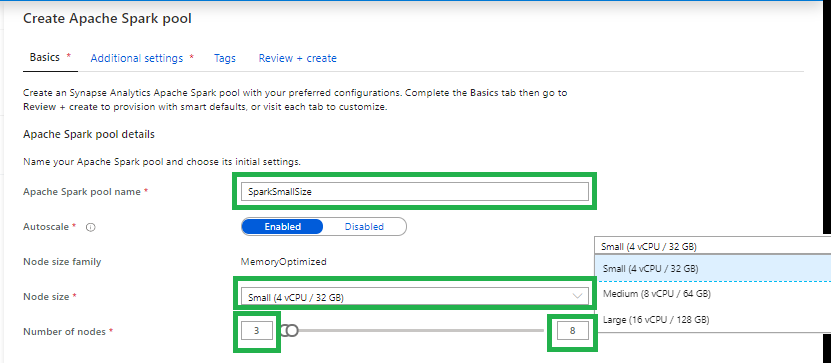
Apache Spark pool name
Note that there are specific limitations for the names that Apache Spark Pools can use. Names must contain letters or numbers only, must be 15 or less characters, must start with a letter, not contain reserved words, and be unique in the workspace.
Node size
Small(4vCPU)
Medium(8vCPU)
Large(16vCPU)
Autoscale
Enabled: Based on your workloads the Spark Pool will scale up or down.
Disabled: You have to define a fix number of nodes.
Number of nodes.
You can select 3 up to 200 nodes
Make sure that
Contact an Owner of the storage account, and verify that the following role assignments have been made:
- Assign the workspace MSI to the Storage Blob Data Contributor role on the storage account
- Assign you and other users to the Storage Blob Data Contributor role on the storage account
Once those assignments are made, the following Spark features can be used: (1) Spark Library Management, (2) Read and Write data to SQL pool databases via the Spark SQL connector, and (3) Create Spark databases and tables.
If you haven’t assign the Storage Blob Data Contributor role to your user, you will get the following error when you want to browse the date in your Linked Workspace.


Currently you can only select Apache Spark version 2.4.
Make sure you enable the Auto Pause settings. If will save you a lot of money. Your cluster will turn off after the configured Idle minutes.
Python packages can be added at the Spark pool level and .jar based packages can be added at the Spark job definition level.
- If the package you are installing is large or takes a long time to install, this affects the Spark instance start up time.
- Packages which require compiler support at install time, such as GCC, are not supported.
- Packages can not be downgraded, only added or upgraded.
How to install these packages can be found here.
Review your settings and your Apache Spark Pool will be created.
You have now created your Apache Spark Pool.
Thanks for reading, in my next article I will explain how to create a SQL Pool, the formerly Azure SQL DW Instance