PASS SQLSaturday is a free training event for professionals who use the Microsoft data platform. These community events offer content across data management, cloud and hybrid architecture, analytics, business intelligence, AI, and more.
My first virtual event
I like to interact during my session, so I’m curious if that will work. Last week I recorded my session for SQL Bits and that is quite strange when you look back. I am really looking forward to it, my session starts at 14:30.
The complete schedule can be found here. Are there is still time to register!!
My Session
Session Title:
Azure Key Vault, Azure Dev Ops and Data Factory how do these Azure Services work perfectly together!
Session Details
Can we store our Connectionstrings or BlobStorageKeys or other Secretvalues somewhere else then in Azure Data Factory(ADF)? Yes you can! You can store these valuable secrets in Azure Key Vault(AKV). But how can we achieve this in ADF? And finally how do we deploy our DataFactories in Azure Dev Ops to Test, Acceptance and Production environments with these Secrets ? Can this be setup dynamically? During this session I will give answers on all of these questions. You will learn how to setup your Azure Key Vault, connect these secrets in ADF and finally deploy these secrets dynamically in Azure Dev Ops. As you can see a lot to talk about during this session.
SQL Saturday 963 Denmark PASS SQLSaturday is a free training event for professionals who use the Microsoft data platform. These community events offer content across data management, cloud and hybrid architecture, analytics, business intelligence, AI, and more. My…
DataWeekender 4.2 This Saturday I’ve joined the Van and Spoke at DataWeekender Azure Purview I presented a session on Azure Purview Microsoft’s answer to Data Governance and Data Lineage You can find my slides below on Slideshare: Data weekender4.2 azure purview erwin…
Data: Scotland 2022 Microsoft Purview Scotland’s Data Community Conference happened this year again in Glasgow. This years event was happening in a sunny Glasgow, more then 400 attendees and more then 50 sessions. It was great to see so many people live again. I…
Scottisch Summit 2021 This Saturday I’ve been speaking during Scottisch Summit 2021. It was my first Summit, but is was a great event, with more than 400 sessions covering the full Microsoft Stack in 7 different language English, Spanish, German, French, Italian,…
Yeah, m y first blog is LIVE After a good talk with Reza Rad from RADACAD during SQLSatHolland, I decided to start my first blog! Knowledge sharing is very important, it gives me a lot of energy. But it also gives others people in the community energies to pick up new…
TechoramaNL 2019 Date: 2 th October Location: Pathé Ede From September 30 th to October 2 nd TechoramaNL was held in the Netherlands for the 2nd time. TechoramaNL is the largest deep knowledge IT conference in the Netherlands with 1500 participants and 120 sessions in…
An inaugural event specializing on Azure Synapse Analytics Data Toboggan This Saturday I’ve been speaking during Data Toboggan an inaugural event specializing on Azure Synapse Analytics. 12 Hours of sessions with amazing speakers. Azure Purview I presented a session…
Data Saturday Stockholm Bra så alla tillbaka personligen This means great so everyone back in person. Last weekend I had the honor to speak at Data Saturday in Stockholm. About one of my favourite topics Azure Synapse Analytics. It was nice to see everyone in person…
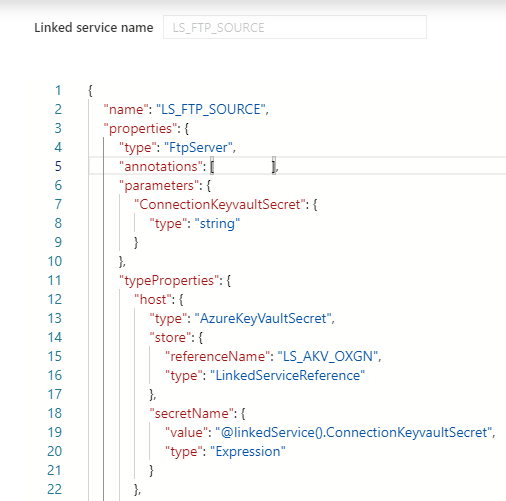
For my Azure Data Factory solution I wanted to Parameterize properties in my Linked Services. Not all properties are Parameterized by default through the UI. But there's another way to achieve this.
Linked Service
Open your existing Linked Services.
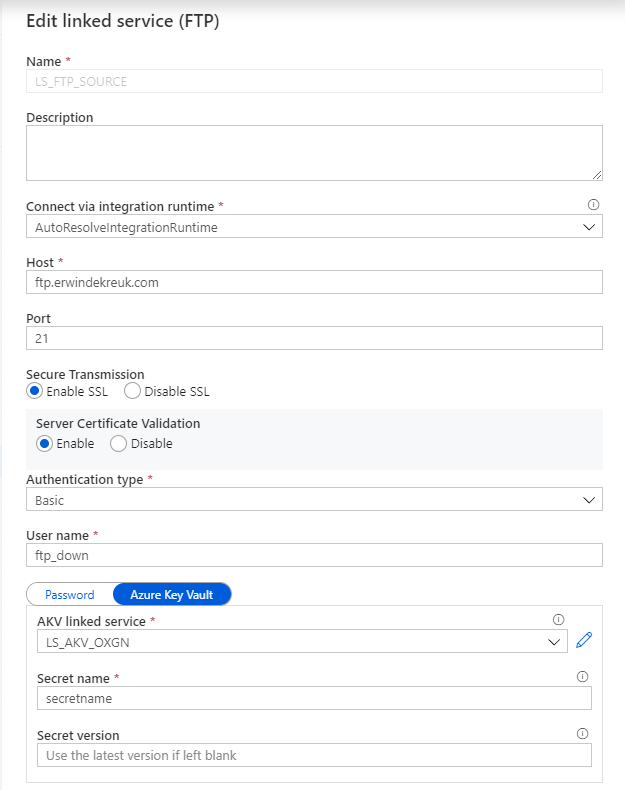
In this situation I want to Parameterize my FTP connection so that I can change the Host name based on a Azure Key Vault Secret.
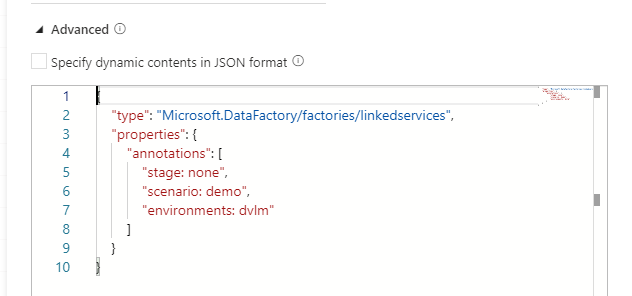
By default is this not possible through the UI but in the Bottom of your Linked Service there is a Advanced box
If you enable this box you can start building your own connection, but also create your own Parameters for this connection.
How to start:
As a base we will use the default code or our connection
After you have done this, you need to specify for which properties you want to use this parameter. In my case I want to read the parameter form my Azure Key Vault for my HOST propertie.
The JSON code below will now use above parameter as an input.
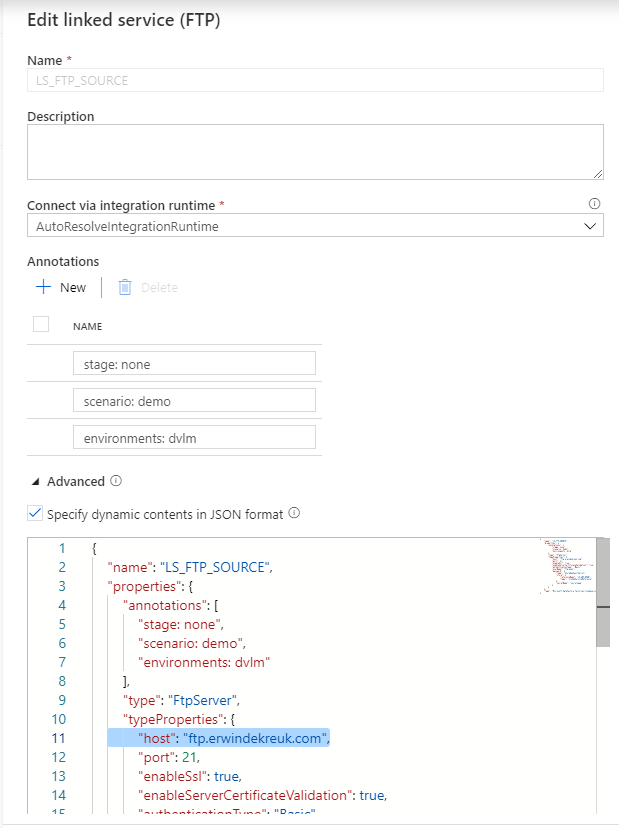
Save your connection and you will see that your UI is changed and that you have to define all your setting through the Advanced Editor.
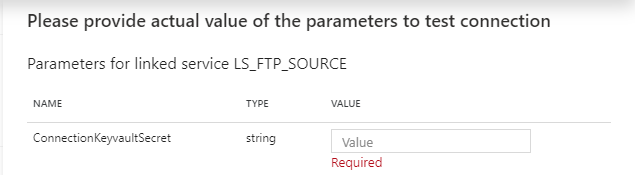
If you test your connection you will now see that you have to fill in a parameter.
And now you can create parameters of every TypeProperties within your connection.
The code below will create Parameters for your Host, Username and Password entries with Azure Key Vault enabled. For the authenticationType you have to choose between Basic and Anonymous. But can also at this to your Azure Key Vault.
More and more projects are using Azure Data Factory and Azure Synapse Analytics, the more important it is to apply a correct and standard naming convention. When using standard naming conventions you create recognizable results across different projects, but you also create clarity for your colleagues. In addition to that, it is easier to add these projects to other services such as Managed Services, Azure DevOps, etc etc, because standards are used.
To start with these naming conventions, I have made a list of suggestions with most common Linked Services. The list is not exhaustive, but it does provide guidance for new Linked Services.
There are a few standard naming conventions that apply to all elements in Azure Data Factory and in Azure Synapse Analytics.
*Names are case insensitive (not case sensitive). For that reason I’m only using CAPITALS.
*Maximum number of characters in a table name: 260.
All object names must begin with a letter, number or underscore (_).
Following characters are not allowed: “.”, “+”, “?”, “/”, “<”, ”>”,”*”,”%”,”&”,”:”,””
These rules are also defined on the following link
This post has been updated on Feb 2nd, 2023 with the latest connectors.
If your connector is not described(mostly connectors which are in Preview), please let me know. For more details for all the different connectors, check the connector overview
Pipeline
Even for Pipeline you can define naming conventions. I think the most important thing is that you always start your pipeline with PL_ followed by a Logic Name for you. You can for example use:
TRANS: Pipeline with transformations
SSIS: Pipeline with SSIS Packages
DATA: Pipeline with DataMovements
COPY: Pipeline with Copy Activities
Divers
NB: Notebook
DF: Mapping Dataflows
SQL: SQL Scripts
KQL: KQL Scripts
JOB: Spark job definition
Once again these naming conventions are just suggestions. The most important thing is that you start using naming conventions and that you use the folder structure within the Pipelines (categories). Like the picture below as an example.
If you have suggestions just let me know by leaving a comment below.
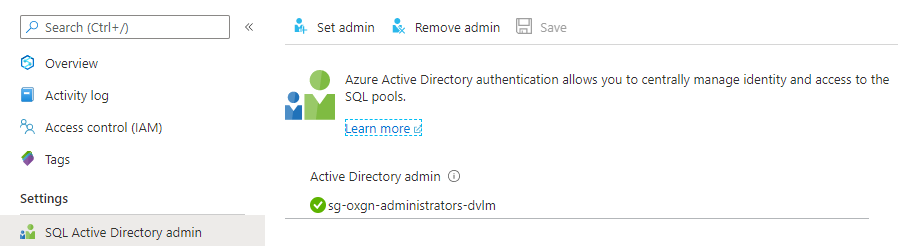
Most configuration and settings can be done through the Synapse Studio. In your Workspace you need to set the SQL Active Directory Admin, like you have to do for a Logical Server.
SQL Active Directory Admin
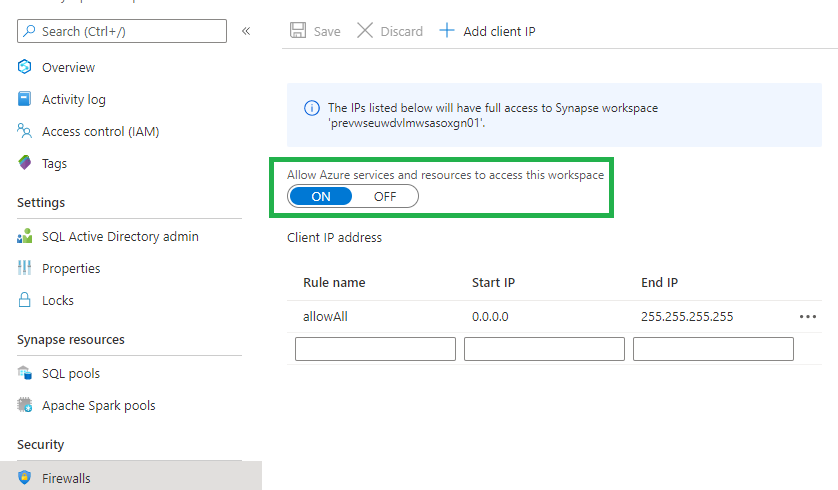
Firewall
Change the IP-address to you own IP-address or to one of your employer if you work from the office. Make sure that you enable the option “Allow Azure service and Resources to access this Workspace” is enabled. Every trusted Azure Service or Resource can connect to this Workspace. Not all Public Preview Azure Services or Resources are Trusted yet.
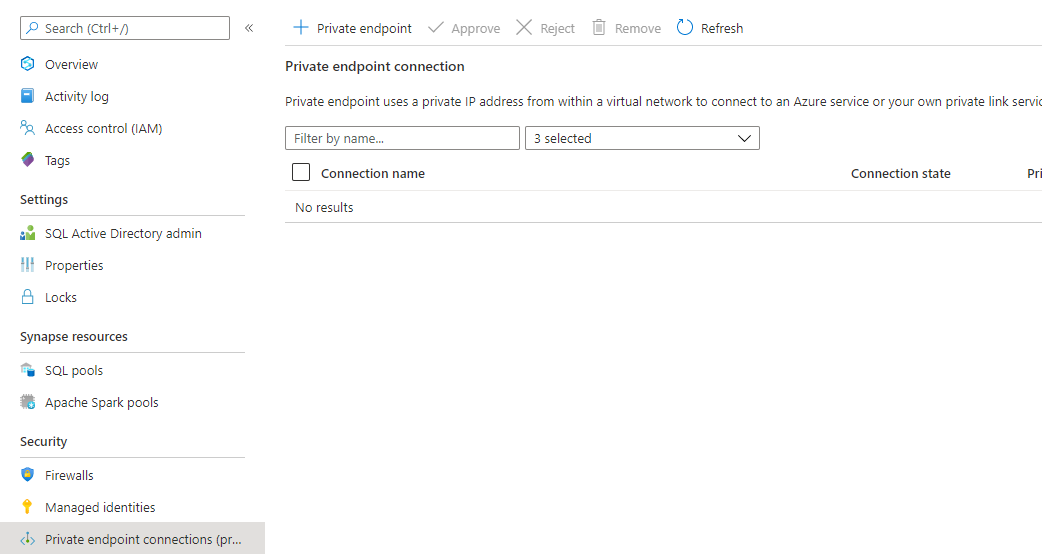
Private Endpoint Connections
Define your Private Endpoint Connections to your Services to use a Private IP-address form your Virtual Network. More details on how to setup a Private Endpoint Connection can be found here.
Launch Azure Synapse Analytics Studio
After you have opened the portal, the following screen will appear. Personally I am very charmed of this brand new Portal, you now get 1 place where you can access all your data. But also an integration with your Power BI reporting. But more about that later. Let’s walk through each tab below.
Data
The data Tab is Divided into 2 different parts Linked and Workspace
Linked
All Dataset likes you’re used to create in Azure Data Factory are stored here.
Your can now directly browse files within your Azure Data Lake Storage.
But you can also connect to External Data.
Workspace
Here you will find all your databases which you have created with Sparks, SQL on Demand or SQL Pools. How to create these database I will explain later in another article.
Develop
The Develop tab, is the location, where your SQL Scripts, Notebooks, Dataflows, Spark Job Definitions and Power BI Reports are stored. In a later stage you can commit your work to Azure Dev Ops or GitHub.
Orchestrate
What do we see here , nothing more then you were used to see in Azure Data Factory except the addition of the Synapse Activities.
Monitor
In the monitor tab you will find similar things to ADF except for the SQL requests and the Apache Spark Applications
Orchestration:
Pipeline runs
Overview of all Executed Pipelines
Trigger Runs
Overview of all Executed Trigger Runs
Integration runtimes
Overview of all created Integration Runtimes
Activities:
Apache Spark applications
Monitor your Apache Spark Executions
SQL requests
Monitor your SQL on Demand or SQL Pool queries
SQL request
All running(currently) SQl request for your SQL on Demand and your SQL Pools
Apache Spark Applications
All Apache Spark request.
A detailed explanation of the Apache Spark Application monitor can be found here.
Management HUB
The Synapse Analytics Management HUB offers the following options:
Analytic Pools:
SQL pools
Here you can manage(Scale up or Down) your previously created SQL pools or create new ones.
Apache Spark pools
Create multiple instances of Spark pools depending on the workload requirements. Once you have your Instance created you also change Auto Scaling, Node Size and Number of Nodes from here.
External Connections:
Linked Services
Create and manage connections to different services, same as in Azure Data Factory
Orchestration:
Triggers
Create and manage Triggers for your Pipelines, same as in Azure Data Factory
Integration runtimes
Create and manage your different types of Integration Runtime: Azure: execute workloads between Azure services or Azure Data Factory Mapping Data Flows. Self-Hosted: execute workloads between on-premises environments and Azure. Azure-SSIS: execute SQL Server Integration Services packages in Azure Data Factory.
Security:
Access control
Azure Synapse Analytics comes with role-based access control. The available roles: Workspace admin Apache Spark admin SQL admin
Managed Private Endpoint
Private link enables you to access Azure services from your Azure VNet securely. More details on Managed Private Endpoints can be found here
At the beginning of this article, I indicated that I was very charmed of this new Portal. Microsoft has ensured that we can now approach almost all our services seamlessly from 1 Portal and there will be much more to come in the future. And as you can see you don’t have to use the SQL Pools which is a reasonably expensive solution for customers who use a lot of data. But you can use Azure Synapse Analytics for almost every customer. I would say if you haven’t started trying Azure Synapse Analytics yet, start today and see how you can help your customers with this. If there are any questions I would like to hear them.
Azure Synapse provides a breathtaking view of your data across data warehouses and big data analytics systems. Bringing these two worlds together into a single service is challenging as it requires unifying similar concepts that operate differently in each world such as security, privacy, and performance. With Azure Synapse, this seamless unification of data warehousing and big data not only simplifies a business’s analytics platform, but also breaks down silos that exist today because of teams, data, and skills. (source Azure blog)
Azure Synapse Analytics Workspace
During Ignite 2019 we already saw the first announcement about Azure Synapse Analytics. The first Public Preview was announced during Build 2020.
Immediately after Build 2020, I started playing and exploring with Azure Synapse Analytics Workspace. Fortunately, I was off for a few days and was able to use this free time to dive a little bit into Azure Synapse.
A few days later during the Analytics in a Day workshops that I gave for my employer InSparkin collaboration with Microsoft, I immediately took the time to give a Live demo. I found the inspiration for this Live demo during a YouTube session presented bySimon Whiteley.
For many participants it is more imaginative, to walk through the product Live than to tell a story via PowerPoint Slides.
Upcoming Articles
In the coming days I will try to write a number of articles so that you become more familiar with the various possibilities of Azure Synapse Analytics.